Investigando Programas de Pós-Graduação em Computação no Brasil (PT 2)
Resumo
Saudações pessoal.
A ideia deste post é compartilhar com vocês um tutorial de como hospedar uma aplicação desenvolvida com o R no shinyapps.io. Por conveniência, vou ilustrar o tutorial com base no Sistema Operacional Ubuntu versão 18.10 LTS.
Os dados que utilizei como base para este app são os dos Programas de Pós-Graduação em Computação do Brasil, já trabalhados anteriormente neste post.
O que eu preciso para reproduzir este experimento?
- Linguagem R versão 3.6.3;
- RStudio versão 1.2.5033 (IDE opcional);
- Conjunto de planilhas com os dados dos Programas de Pós-Graduação em Computação do Brasil;
- Uma conta no shinyapps.io;
- Conhecimentos básicos de lógica e programação, estruturas de dados e R.
Tópicos
-
Quais informações vamos trazer aos usuários?
-
Coleta e organização dos dados;
-
Elaboração da Interface do Usuário (User Interface - UI);
-
Elaboração da lógica do servidor (Server);
-
Execução do app na própria máquina (localmente);
-
Publicando o app no shinyapps.io;
Quais informações vamos trazer aos usuários?
Não adianta avançarmos para os tópicos técnicos do desenvolvimento sem antes termos clareza do propósito deste app. A idéia é fornecer um meio de consulta aos locais do Brasil onde existem Programas de Pós-Graduação em Computação com filtros para parâmetros específicos como tema de pesquisa, localização, conceito da CAPES, nível do programa, entre outros. Também pretende-se gerar informações sobre as linhas de pesquisa destes Programas, como surgimento com o passar dos anos e número total no país.
Portanto, foram elencadas as seguintes propostas de informações:
-
Localização (GPS) dos Programas de Pós-Graduação em Computação do Brasil, com filtros por Unidade da Federação (estados), universidade, linha de pesquisa e conceito da CAPES (gráfico de mapa);
-
Quantitativo de Programas por estado (gráfico de barras);
-
Total de Programas por temas de pesquisa (gráfico de barras);
-
Número de Programas com determinado tema de pesquisa com o passar dos anos (com possibilidade de comparação com outro tema) (gráfico de linhas);
Coleta e Organização dos Dados
Na Parte 1, eu coletei os dados dos Programas e salvei em arquivos no formato csv. Estes dados foram obtidos de dois locais, entre 10/2019 e 01/2020:
-
Página Oficial de cada um dos Programas de Pós-Graduação em Computação do Brasil;
Eu coletei estes dados manualmente, organizei e salvei em arquivos csv no formato normalizado (com id e fk). Para maiores detalhes deste processo, acesse a parte 1 deste projeto.
Antes de começar, você tem duas alternativas: Clonar o meu projeto do github, utilizar o setwd para o diretório raiz do projeto e acompanhar este tutorial ou fazer o download do diretório csv e shapefile para o diretório do seu projeto e seguir este tutorial.
Abaixo são apresentados os pacotes utilizados na primeira parte do tutorial. O código fonte completo está disponível no Github.
# loading / installing packages
#sudo apt install default-jdk -> rjava package dependency
if (!require(xlsx)) install.packages("xlsx")
library(xlsx)
#sudo apt install libgdal-dev -> https://stackoverflow.com/questions/12141422/error-gdal-config-not-found
if (!require(rgdal)) install.packages("rgdal")
library(rgdal)
if (!require(rgeos)) install.packages("rgeos")
library(rgeos)
if (!require(ggplot2)) install.packages("ggplot2")
library(ggplot2)
if(!require(maptools)) install.packages("maptools")
library(maptools)
if (!require(dplyr)) install.packages("dplyr")
library(dplyr)
if (!require(forcats)) install.packages("forcats")
library(forcats)
Inicialmente, vamos importar e organizar esses dados para obter as informações necessárias para a UI.
# importação dos dados
universities_path <- "../csv/universities_after.xlsx"
cities_path <- "../csv/brazilian_cities.csv"
states_path <- "../csv/brazilian_states.csv"
research_names_path <- "../csv/research_names.xlsx"
university_research_path <- "../csv/university_research.xlsx"
graduation_level_path <- "../csv/graduation_level.xlsx"
course_name_path <- "../csv/course_name.xlsx"
concentration_area_path <- "../csv/concentration_area.xlsx"
university_concentration_area_path <- "../csv/university_concentration_area.xlsx"
universities <- read.xlsx(universities_path, stringsAsFactors = FALSE, sheetIndex = 1, encoding = "UTF-8")
brazilian_cities <- read.csv(cities_path, sep = ",", stringsAsFactors = FALSE, encoding = "UTF-8")
brazilian_states <- read.csv(states_path, sep = ",", stringsAsFactors = FALSE, encoding = "UTF-8")
research_names <- read.xlsx(research_names_path, sheetIndex = 1, encoding = "UTF-8")
university_research <- read.xlsx(university_research_path, sheetIndex = 1, encoding = "UTF-8")
graduation_level <- read.xlsx(graduation_level_path, sheetIndex = 1, encoding = "UTF-8")
course_name <- read.xlsx(course_name_path, sheetIndex = 1, encoding = "UTF-8")
concentration_area <- read.xlsx(concentration_area_path, sheetIndex = 1, encoding = "UTF-8")
university_concentration_area <- read.xlsx(university_concentration_area_path, sheetIndex = 1, encoding = "UTF-8")
# união dos dados em um único dataframe
all_data <- inner_join(universities, brazilian_cities, by = c("city_id" = "ibge_code"))
all_data <- inner_join(all_data, brazilian_states, by = c("state_id" = "state_id"))
all_data <- inner_join(all_data, university_research, by = c("id" = "university_id"))
all_data <- inner_join(all_data, research_names, by = c("research_id" = "id"))
all_data <- inner_join(all_data, graduation_level, by = c("level" = "id"))
all_data <- inner_join(all_data, course_name, by = c("course" = "id"))
all_data <- inner_join(all_data, university_concentration_area, by = c("id" = "university_id"))
all_data <- inner_join(all_data, concentration_area, by = c("concentration_area_id" = "id"))
# colunas de ID descartadas, dados para formato numérico (limpeza e preparação dos dados)
all_data <- all_data[,-9]
all_data <- all_data[,-14]
all_data <- all_data[,-16]
all_data <- all_data[,-19]
all_data$latitude <- as.numeric(as.character(all_data$latitude))
all_data$longitude <- as.numeric(as.character(all_data$longitude))
all_data$grade <- as.numeric(as.character(all_data$grade))
# importação do shapefile
shape_brazil_path <- "../../shapefile/Brazil.shp"
shape_brazil <- readOGR(shape_brazil_path, "Brazil", encoding = "latin1")
# transformação do shapefile para dataframe
shape_brazil$id <- rownames(as.data.frame(shape_brazil))
coordinates_brazil <- fortify(shape_brazil, region = "id") # apenas coordenadas
shape_brasil_df <- merge(coordinates_brazil, shape_brazil, by = "id", type = 'left') # acréscimo de atributos restantes
Com os dados importados e organizados em dataframes, agora vamos criar dataframes específicos para cada um dos gráficos na UI. Isso fará com que a aplicação consuma mais memória, mas por outro lado tornará a lógica de processamento e acesso aos dados mais simples.
# dados agrupados por estado e id, ordem decrescente de n° de Programas por estado
barplot_1_data <- as.data.frame(
all_data %>%
group_by(state_code) %>%
summarise(id = n_distinct(id)) %>%
arrange(-id) %>%
mutate(state_code = fct_reorder(state_code, -id))
)
# dados agrupados por tópico de pesquisa e id, especificamente os tópicos que aparecem no mínimo 10 vezes, em ordem decrescente de n° de Programas por tópico
barplot_2_data <- as.data.frame(
all_data %>%
group_by(research_name) %>%
summarise(id = n_distinct(id)) %>%
arrange(-id) %>%
mutate(research_name = fct_reorder(research_name, -id)) %>%
filter( id > 10 )
)
# dados agrupados por tópico de pesquisa e ano, ordenados por ano, agregando o n° de Programas por tópico de pesquisa por ano
lineplot_1_data <- as.data.frame(
all_data %>%
group_by(research_name, year) %>%
summarise(id = n_distinct(id)) %>%
arrange(year) %>%
mutate( cumsum = cumsum(id))
)
# valores possíveis de notas da CAPES
mybreaks <- c("3", "4", "5", "6", "7")
O código acima (em lineplot_1_data) tem um problema: é feito o agrupamento do n° de Programas por linha de pesquisa e por ano, porém não são gerados registros para os anos em que não houve variação do n° de Programas. Abaixo um exemplo:
1995 surgiu 1 novo tópico de pesquisa em IA e havia 12 tópicos de pesquisa em IA. Portanto, 1995 passou a ter 13 Programas em IA.
1996 surgiram 2 novos tópicos de pesquisa em IA e havia 13 tópicos de pesquisa em IA. Portanto, 1995 passou a ter 15 Programas em IA.
1997 não surgiu nenhum novo tópico em IA. Nesse caso, não é gerado registro para 1997, causando distorções nos gráficos.
O algoritmo abaixo foi feito para gerar registros nos anos em que o número de tópicos de pesquisa não variou, para todos anos e tópicos de pesquisa.
# gerando registros para os anos sem variação no n° de Programas para cada tópico de pesquisa
for( i in 1:length(unique(lineplot_1_data$research_name)) ) {
name <- as.character(unique(lineplot_1_data$research_name)[i])
last_year <- 0
last_cumsum <- 0
for (j in min(lineplot_1_data$year):max(lineplot_1_data$year) ) {
if (j %in% lineplot_1_data$year[lineplot_1_data$research_name == name]){
last_year <- j
last_cumsum <- lineplot_1_data$cumsum[lineplot_1_data$research_name == name & lineplot_1_data$year == j]
}
else {
lineplot_1_data <- rbind.data.frame(lineplot_1_data, c(name, j, 0, last_cumsum), stringsAsFactors = FALSE)
}
}
}
lineplot_1_data$year <- as.numeric(lineplot_1_data$year)
lineplot_1_data$id <- as.numeric(lineplot_1_data$id)
lineplot_1_data$cumsum <- as.numeric(lineplot_1_data$cumsum)
lineplot_1_data <- lineplot_1_data[order(lineplot_1_data$year),]
Também foram realizadas customizações para cada gráfico que será gerado na UI. Abaixo é apresentado o código para customizar o tema (dark theme) e layout dos gráficos. O nome das variáveis já indica em qual gráfico que será aplicado o tema. Também são definidos os textos das escalas X e Y de cada gráfico.
geral_1_theme <- theme(
axis.text = element_text(size = 12, color = "#cccccc"),
axis.title = element_text(size = 16, face = "bold", color = "#cccccc"),
axis.ticks = element_line(colour = "#cccccc"),
axis.ticks.length = unit(0.5, "cm"),
plot.caption = element_text(size = 12, face = "bold", color = "#cccccc"),
plot.title = element_text(size = 22, hjust = 0.5, color = "#ffffff"),
plot.background = element_rect(fill = "black"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = 'black'),
legend.background = element_rect(fill = "black", color = NA),
legend.key = element_rect(color = "gray", fill = "black"),
legend.text = element_text(size = 14),
text = element_text(color = "#cccccc")
)
map_labs <- labs(
x = "Longitude",
y = "Latitude",
caption = "Fonte: Programas de Pós-Graduação em Computação - Plataforma Sucupira."
)
barplot_1_labs <- labs(
x = "\nEstados do Brasil",
y = "\nNúmero de Programas\n",
caption = "\nFonte: Programas de Pós-Graduação em Computação - Plataforma Sucupira."
)
barplot_2_labs <- labs(
y = "Número de Programas de Pós-Graduação",
caption = "\nFonte: Programas de Pós-Graduação em Computação - Plataforma Sucupira."
)
lineplot_1_labs <- labs(
x = "\nAnos",
y = "Número de Programas\n",
caption = "\nFonte: Programas de Pós-Graduação em Computação - Plataforma Sucupira."
)
Agora salvamos nosso ambiente (variáveis, dados e pacotes) em um arquivo RData. Depois ele será importado no servidor da aplicação (entenda o servidor/server como o backend, responsável pela lógica do app, processamento de inputs e geração dos gráficos com as informações processadas) e na interface da aplicação (para a geração de alguns menus para inputs do usuário).
save.image(file = "R/data/all_data.RData")
Elaboração da Interface do Usuário (User Interface - UI)
Agora devemos preparar a UI com os gráficos para o usuário. Abaixo o código utilizado para gerar a UI.
if (!require(shiny)) install.packages("shiny")
library(shiny)
if (!require(shinydashboard)) install.packages("shinydashboard")
library(shinydashboard)
load(file = "data/all_data.RData")
ui <- navbarPage(
"Tek Broom",
tabPanel(
"Mapas",
fluidPage(id = 'fluidPage',
shinyjs::useShinyjs(),
titlePanel("Programas de Pós-Graduação em Computação - Brasil"),
sidebarLayout(
sidebarPanel(id = "sidebar",
selectInput(
"input_state",
"Estado",
choices = c("Todos", sort(unique(all_data$state_name))),
selected = "Todos"
),
selectInput(
"input_university",
"Universidade",
choices = c("Todas", as.character(sort(unique(all_data$university)))),
selected = "Todas"
),
selectInput(
"input_research_topic",
"Assunto de Pesquisa",
choices = c("Todos", as.character(sort(unique(all_data$research_name)))),
selected = "Todos"
),
sliderInput(
"input_grade_range",
label = "Notas dos Programas:",
min = 3,
max = 7,
value = c(3, 7)
)
),
mainPanel(id = 'mainPanel',
fluidRow(box(
background = "black",
plotOutput("map", height = 900), width = 12 )))
),
includeCSS("css/styles.css"))
),
tabPanel(
"Gráficos",
dashboardPage(
dashboardHeader(disable = TRUE),
dashboardSidebar( disable = TRUE),
dashboardBody(
fluidRow(
box(
background = "black",
title = "Programas de Pós-Graduação em Computação por Estado",
solidHeader = TRUE,
collapsible = TRUE,
plotOutput("barplot_1"),
width = 6
)
,
box(
background = "black",
title = "Programas de Pós-Graduação em Computação por Tópico de Pesquisa",
solidHeader = TRUE,
collapsible = TRUE,
plotOutput("barplot_2"),
width = 6
)
),
fluidRow(
box(
background = "black",
title = "Histórico dos Programas de Pós-Graduação em Computação por Tópico de Pesquisa",
solidHeader = TRUE,
collapsible = TRUE,
"Observação: o ano apresentado é o de surgimento do Programa que originou
o Tópico de Pesquisa. Não é o ano de surgimento do Tópico de Pesquisa em si,
já que a informação dos tópicos de pesquisa não foi coletada do site da
CAPES e sim da página de cada Programa de Pós-Graduação em Computação do
Brasil.",
br(),br(),br(),
plotOutput("lineplot_1"),
width = 12
),
box(
background = "black",
box(
background = "black",
selectInput(
"input_research_1",
"Tópico de Pesquisa 1",
choices = sort(unique(lineplot_1_data$research_name)),
selected = lineplot_1_data$research_name[1]
)
),
box(
background = "black",
selectInput(
"input_research_2",
"Tópico de Pesquisa 2",
choices = c("Nenhum", as.character(sort(unique(lineplot_1_data$research_name)))),
selected = "Nenhum"
)
),
width = 12
)
)
)
)
)
)
Antes de explicar em detalhes cada componente da UI, cabe mostrar o que é cada um destes componentes na tela final do shinyapp. Abaixo são apresentadas duas telas do nosso app final, com destaque para cada componente da UI.
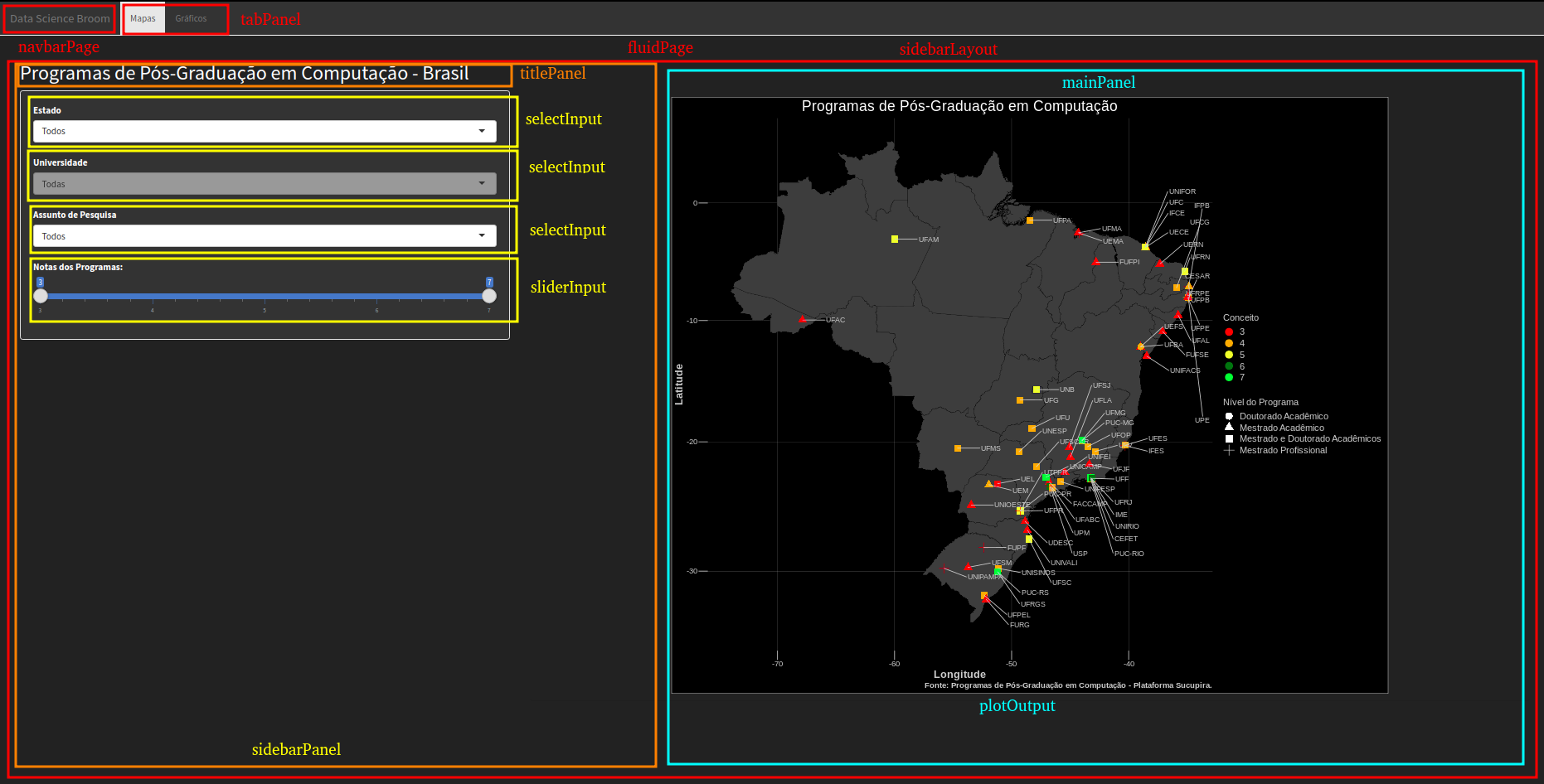
navbarPage - cria uma página com a possibilidade de menus no topo;
tabPanel - cria um menu no painel que é aplicado;
fluidPage - cria páginas com layout adaptável, definidas por largura e altura (width e height);
titlePanel - título do painel onde é aplicado;
sidebarLayout - estilo de layout aplicado na página. O layout sidebar contém um painel lateral e a área principal;
sidebarPanel - cria um painel lateral;
selectInput - input de dados no estilo menu dropdown;
sliderInput - input de dados no estilo slider;
mainPanel - painel com a área principal da página;
plotOutput - local onde é plotado o gráfico “map”.
Na página dos gráficos, apenas para fins didáticos e de autoaprendizado, utilizei o shiny dashboards. Abaixo uma breve explicação de cada componente.
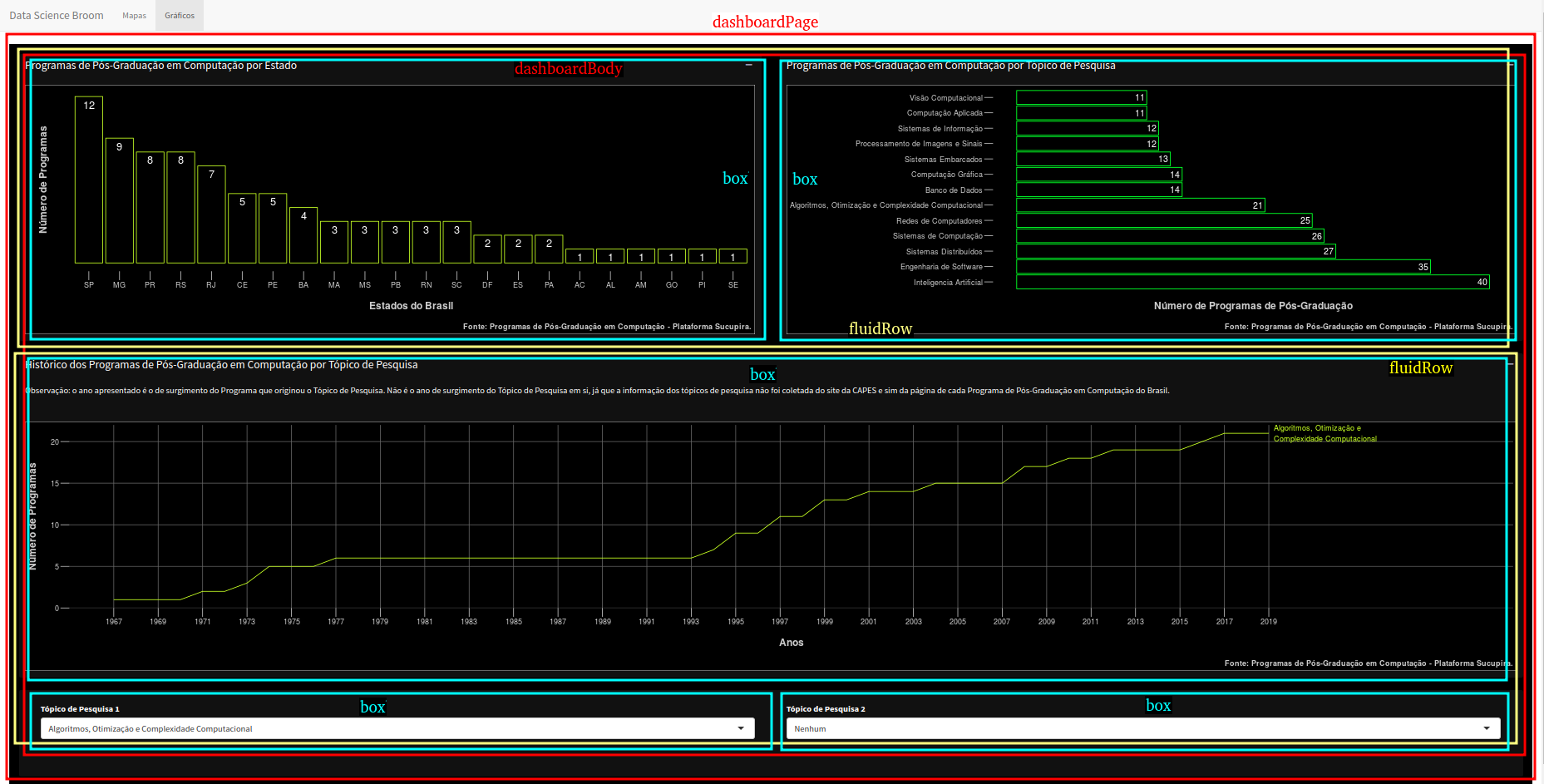
dashboardPage - cria uma página com shiny dashboard;
dashboardHeader - componente header da página, que no nosso caso está desabilitado (disable = TRUE);
dashboardSidebar - componente da barra lateral, que no nosso caso também está oculto (collapsed = TRUE);
dashboardBody - área principal do dashboard, corpo da página;
fluidRow - componente para geração de linhas e colunas baseada no bootstrap;
box - principal componente de um shinydashboard, que pode conter outros elementos shiny, inputs, outputs de dados, gráficos e outros.
Para maiores detalhes dos componentes do shiny, acessem este link.
E para detalhes dos componentes do shinyDashboard, acessem este link.
Cabe destacar três elementos em especial:
load(file = “data/all_data.RData”) aqui importamos os dados que processamos no início deste tutorial, pois vamos precisar do dataframe all_data para fornecer as opções de estados e universidades nos selects para os usuários. Também vamos precisar dos nomes das linhas de pesquisa para um dos gráficos.
shinyjs::useShinyjs() utilizamos o shinyjs para habilitar e desabilitar o input de dados, em certas condições. Ex: se eu quero ver todos os Programas de Pós do Brasil, devo desabilitar a seleção de universidade. O código para isso está no server.R.
includeCSS(“css/styles.css”)) este trecho de código permite customizar o estilo da nossa página. Nesse caso, alteramos a página original para um dark theme.
#fluidPage {
background-color: #222222;
color: #ffffff;
}
body {
background-color: #222222;
color: #ffffff;
}
.content-wrapper, .right-side {
background-color: #000000;
}
#sidebar {
background-color: #333333;
color: #ffffff;
}
#mainPanel {
background-color: #222222;
color: #ffffff;
}
.navbar-default {
background-color: #333333;
border-color: #ffffff;
}
.bg-black {
background-color: #222222 !important;
}
Em resumo:
-
A variável ui armazenará os componentes para a geração da interface gráfica para o usuário. Nossa interface terá duas abas: Mapas e Gráficos, definidas em tabPanel. A aba Mapas permitirá ao usuário fazer consultas com o resultado exibido em mapas e a aba Gráficos permitirá ao usuário visualizar informações gerais dos Programas e linhas de pesquisa em gráficos de barras e linhas.
-
Aba Mapas: essa tela possuirá um componente sidebar (barra lateral) onde serão inseridos os inputs (entrada de dados) para a geração dos mapas e o restante da tela é onde o mapa será apresentado. titlePanel é o título da barra lateral, sidebarLayout é o layout da página (com barra lateral) e sidebarPanel terá os componentes que desejamos para essa barra lateral (inputs para seleção dos Programas por estado, universidade, linha de pesquisa e conceito da CAPES).
-
Aba Gráficos: essa tela terá três gráficos. Um gráfico de barras verticais para a exibição do total de Programas por estado, um gráfico com barras horizontais com as linhas de pesquisa no Brasil com no mínimo 10 em número de Programas (com no mínimo 10) e um gráfico de linhas com a evolução do número de Programas para as linhas de pesquisa selecionadas (uma ou duas linhas de pesquisa por vez).
A UI se resume a isso. Agora vamos para o server xD (parte mais complicada, em termos de lógica).
Elaboração da lógica do servidor (Server);
O nosso server será responsável por processar os inputs do usuário para gerar os gráficos adequados em cada situação possível.
Vamos criar um arquivo com o nome server.R e instalar/importar os seguintes pacotes, além de carregar os dados que organizamos no início do tutorial:
if (!require(dplyr)) install.packages("dplyr")
library(dplyr)
if (!require(ggplot2)) install.packages("ggplot2")
library(ggplot2)
if(!require(RColorBrewer)) install.packages("RColorBrewer")
library(RColorBrewer)
if(!require(viridis)) install.packages("viridis")
library(viridis)
if (!require(shinyjs)) install.packages("shinyjs")
library(shinyjs)
if(!require(ggrepel)) install.packages("ggrepel")
library(ggrepel)
if (!require(shiny)) install.packages("shiny")
library(shiny)
if (!require(directlabels)) install.packages("directlabels")
library(directlabels)
if (!require(mapproj)) install.packages("mapproj")
library(mapproj)
if (!require(stringr)) install.packages("stringr")
library(stringr)
load(file = "data/all_data.RData")
O primeiro trecho de código em observe trata o princípio de modificar o input da página dos mapas nas seguintes situações:
- Ao selecionar “Todos os Estados”, o input de Universidade é desabilitado;
- Ao selecionar um estado específico, o input de Universidade deve conter apenas opções de universidade para o estado selecionado;
- Se uma universidade específica for selecionada, o input de Estado é desabilitado;
# Server logic ----
server <- function(input, output, session) {
observe({
if (input$input_state != "Todos") {
shinyjs::enable("input_university")
states <- c("Todas", as.character(sort(unique(all_data$university[which(all_data$state_name == input$input_state)]))))
updateSelectInput(session, "input_university", choices = states, selected = input$input_university)
} else {
shinyjs::disable("input_university")
}
if (input$input_university == "Todas") {
shinyjs::enable("input_state")
} else {
shinyjs::disable("input_state")
}
})
Agora precisamos modificar o conjunto de dados que será plotado na tela de acordo com os inputs do usuário.
A variável map_data armazenará o conjunto de dados adequado para exibição no nosso mapa. Vamos utilizar o reactive do shiny para realizar essa tarefa: sempre que algum input for alterado na interface, o código em reactive no server irá executar e atualizar o conjunto de dados.
Essa lógica se resume a uma série de condicionais (if else), considerando todas as possibilidades de input do usuário (estado, universidade, linha de pesquisa e intervalo de notas da CAPES). A lógica pode ser analisada logo abaixo.
map_data <- reactive({
if(input$input_state == "Todos") {
if(input$input_university == "Todas") {
if(input$input_research_topic == "Todos") {
map_data <- all_data[all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
} else {
map_data <- all_data[all_data$research_name == input$input_research_topic & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
}
} else {
if(input$input_research_topic == "Todos") {
map_data <- all_data[all_data$university == input$input_university & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
} else {
map_data <- all_data[all_data$university == input$input_university & all_data$research_name == input$input_research_topic & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
}
}
} else {
if(input$input_university == "Todas") {
if(input$input_research_topic == "Todos") {
map_data <- all_data[all_data$state_name == input$input_state & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
} else {
map_data <- all_data[all_data$state_name == input$input_state & all_data$research_name == input$input_research_topic & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
}
} else {
if(input$input_research_topic == "Todos") {
map_data <- all_data[all_data$university == input$input_university & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
5 } else {
map_data <- all_data[all_data$university == input$input_university & all_data$research_name == input$input_research_topic & all_data$grade >= input$input_grade_range[1] & all_data$grade <= input$input_grade_range[2],]
}
}
}
})
Também vamos customizar o formato do mapa quando um estado específico for selecionado. Para isso, vamos utilizar novamente o reactive do shiny para selecionar apenas o shape do estado selecionado ou o shape de todo o Brasil caso a opção “Todos” seja selecionada. O shape será salvo na variável map_shapes.
map_shapes <- reactive({
if(input$input_state != "Todos") {
map_shapes = shape_brasil_df[which(shape_brasil_df$ESTADOS == input$input_state),]
} else{
map_shapes = shape_brasil_df
}
})
Na outra tela teremos um gráfico da evolução de uma determinada linha de pesquisa (ou duas, se o usuário desejar) com o passar dos anos. Por padrão, apenas uma será exibida. Para isso, haverão dois inputs do estilo select para a seleção das linhas de pesquisa. Portanto, para determinar se o gráfico deve possuir uma ou duas linhas, será utilizado o dado informado no select do usuário. A opção “Nenhum” foi definida como padrão para a segunda linha de pesquisa (ver código da UI) e indica que o gráfico deve exibir apenas uma linha. Qualquer outra opção neste mesmo menu acarreta na exibição de duas linhas (uma para cada linha de pesquisa selecionada).
Um detalhe importante: repare o dataframe está sendo utilizado no ifelse… Não é o all_data, que contém todos os dados. É o lineplot_1_data. Aquele dataframe com os dados já processados para o gráfico com análise de dados anuais das linhas de pesquisa no Brasil.
line_data <- reactive({
line_data <- if (input$input_research_2 == "Nenhum") lineplot_1_data[lineplot_1_data$research_name == input$input_research_1,]
else lineplot_1_data[lineplot_1_data$research_name == input$input_research_1 | lineplot_1_data$research_name == input$input_research_2,]
})
Por fim, as variáveis output apresentadas na sequência vão receber o conteúdo de renderPlot, que são os gráficos para cada situação.
1- Mapa dos Programas de Pós-Graduação em Computação do Brasil
output$map <- renderPlot({
validate(
need(nrow(map_data()) != 0, 'Para esta(s) universidade(s) não há o selecionado tema de pesquisa!'),
need(map_shapes(), 'Selecione um estado válido.')
)
ggplot() +
geom_polygon(data = map_shapes(), aes(x = long, y = lat, group = group), fill = "#3d3d3d", color = "black", size = 0.15) +
geom_point(data = map_data()[!duplicated(map_data()$code),], aes(x = longitude, y = latitude, color = as.factor(grade), size = 10, shape = graduation_level)) +
scale_color_manual(name = "Conceito", breaks = mybreaks, values=c("red", "orange", "yellow", "darkgreen", "green")) +
scale_shape_discrete(name = "Nível do Programa") +
coord_map() +
guides(colour = guide_legend(override.aes = list(size = 5)), shape = guide_legend(override.aes = list(size = 5, color = "white")), size = FALSE) +
ggtitle("Programas de Pós-Graduação em Computação") +
geom_text_repel(data = map_data()[!duplicated(map_data()$code),], aes(x = longitude, y = latitude, label = code), hjust = 0, nudge_x = 2, direction = "y", color = "#cccccc") +
map_labs + geral_1_theme + theme( panel.grid.minor.y = element_line(size =.1, color = "grey"),
panel.grid.minor.x = element_line(size =.1, color = "grey"),
panel.grid.major.y = element_line(size =.1, color = "grey"),
panel.grid.major.x = element_line(size =.1, color = "grey"),
legend.key = element_rect(color = "black", fill = "black"))
}, bg = "transparent", execOnResize = TRUE)
A função validate serve para validar determinadas variáveis. No nosso caso, verificamos se map_data, o dataframe com os dados processados anteriormente no server, possui registros. Se não possuir, o app vai exibir a mensagem ‘Para esta(s) universidade(s) não há o selecionado tema de pesquisa!’. Também é verificado se map_shapes foi atribuido corretamente, caso contrário a mensagem ‘Selecione um estado válido.’ é exibida.
Por fim, decidi utilizar o ggplot para gerar o mapa. As formas do polígono do mapa (shape) estão em map_shape na função geom_polygon, com latitude na coordenada X, longitude na coordenada Y, variável de agrupamento dos polígonos na coluna group, fundo do mapa na cor cinza (fill) e polígonos de cor preta (color). Para plotar os pontos, foi necessário diferenciar os programas pela cor e pela forma (shape).
Em geom_point foi utilizado o dataframe com os dados dos programas map_data(), utilizando-se um único registro por universidade (!duplicated()), com a posição de cada ponto definida pela latitude e longitude em X e Y, cor do ponto de acordo com a nota da CAPES (de 3 até 7) em color e o formato do ponto (shape)de acordo com o nível do programa (se mestrado profissional, acadêmico, doutorado, ou ambos mestrado e doutorado).
scale_color_manual foi utilizado para definir manualmente as cores utilizadas, que representam a nota da CAPES dos programas. Escolhi por cores bem claras para constrastar com o tema dark.
scale_shape_discrete foi usado para dar o nome da legenda do shape, que vai representar o nível do programa.
coord_map aplica a projeção de mercator no mapa, deixando ele visualmente proporcional.
guides garante que legendas para shape e color serão usadas, e não para size, além de customizações específicas para cada legenda.
ggtitle é o título do mapa.
geom_text_repel serve para plotar textos no gráfico, com uma certa distância do ponto onde seria originalmente desenhado. O texto no nosso caso será a sigla da universidade onde existem programas de pós em computação. Deixo como exercício descobrirem a lógica deste elemento :P
map_labs + geral_1_theme são características do tema dark para os gráficos. Esses temas definimos no início deste tutorial.
E theme foi utilizado para aplicar propriedades específicas deste gráfico.
bg = “transparent”, execOnResize = TRUE são argumentos do renderPlot que permitem gerar novamente o gráfico ao redimensionar a tela e torna o background da figura transparente (se removermos, aparecerá um fundo branco misterioso sempre que redimensionamos o plot).
2- Gráfico de barras com o número de Programas de Pós em Computação por estado.
output$bar_1 <- renderPlot({
ggplot(data = barplot_1_data, aes(x = state_code, y = id)) +
geom_bar(stat = "identity", fill = "black", color = "#E4F00A" ) +
geom_text(data = barplot_1_data, aes(label = id), vjust = 1.6, color = "white", size = 6) +
scale_y_continuous(breaks = seq(0, max(barplot_1_data$id), 2)) +
barplot_1_labs + geral_1_theme + theme(axis.text.y = element_blank(), axis.ticks.y = element_blank())
})
Vale destacar o uso do geom_bar para gerar gráfico de barras e o uso do scale_y_continuous para definir que a escala Y seja sempre uma sequência entre 0 e o estado com o maior número de programas, somado de 2 em 2. geom_text vai exibir na barra o número de programas daquele estado. O restante é semelhante ao gráfico do mapa.
3- Gráfico de barras com o número de Programas de Pós em Computação por linha de pesquisa (apenas tópicos de pesquisa com mais de 10 Programas de Pós).
output$bar_2 <- renderPlot({
ggplot(data = barplot_2_data, aes(x = research_name, y = id)) +
geom_bar(stat = 'identity', fill = "black", color = "#22FF00") +
geom_text(data = barplot_2_data, aes(label = id), hjust = 1.2, color = "white", size = 5) +
scale_y_continuous(breaks = seq(0, max(barplot_2_data$id), 5)) +
coord_flip() +
barplot_2_labs + geral_1_theme + theme(axis.title.y = element_blank(), axis.text.x = element_blank(), axis.ticks.x = element_blank())
})
Vale destacar novamente o scale_y_continuous para definir que a escala Y seja sempre uma sequência entre 0 e o estado com o maior número de programas, somado de 5 em 5. coord_flip() inverte as coordenadas X e Y. O restante já foi abordado.
4- Gráfico de linhas com o número de Programas de Pós em Computação por linha de pesquisa por ano.
output$line_1 <- renderPlot({
ggplot(data = line_data(), aes(x = year, y = cumsum, group = research_name)) +
geom_line(aes(color = research_name)) +
scale_color_manual(values = c("#E4F00A", "#22FF00")) +
guides(colour = FALSE) +
scale_x_continuous(expand = c(0, 0), limits = c(1965, 2030), breaks = seq(min(line_data()$year), max(line_data()$year), 2)) +
lineplot_1_labs + geral_1_theme + theme(panel.grid.major = element_line(color = "#666666")) +
geom_dl(aes(label = str_wrap(research_name, 30), color = research_name), method = list(cex = 1, dl.trans(x = x + .3), "last.qp"))
})
}
Foi usado o geom_line para gerar o gráfico de linhas. O scale_x_continuous foi usado para definir que a escala X seja sempre uma sequência entre o menor e o maior ano, somados de 2 em 2, com limites em 1965 e 2030. geom_dl() foi utilizado para plotar o nome da linha de pesquisa no último ponto na coordanada X, no final da linha.
E com isso, concluímos o lado server da nossa aplicação shiny !! :-)
Bora rodar a aplicação então !!
Execução do app na própria máquina (localmente);
Agora vamos estruturar os diretórios e arquivos da nossa aplicação no seguinte formato (se você clonou o projeto do github, a estrutura de diretório deve estar igual):
- shinyapp (diretório do nosso app) contendo os seguintes arquivos:
+ server.R (server da aplicação)
+ ui.R (interface da aplicação)
+ data (diretório com o seguinte arquivo):
- all_data.RData (ambiente com dados e pacotes, gerado pelo get_data.R)
+ css (diretório com o seguinte arquivo);
- styles.css (customização de alguns elementos do shiny para o tema dark)
Não vamos incluir o arquivo que gerou os temas e dataframes a partir dos csvs, pois esse processamento só foi necessário uma vez, com o objetivo de gerar o arquivo all_data.RData com os nossos dados e pacotes. all_data.RData sim será incluído, e está no diretório data.
Para rodar o app, basta abrir o RStudio no diretório do app, carregar o pacote shiny e executar o seguinte comando:
runApp()
Se foi exibida uma tela com um mapa, semelhante a primeira figura do mapa deste tutorial, parabéns !! Este é o app que vocês desenvolveram comigo em pleno funcionamento !! Façam alguns testes com os inputs para verificar se está tudo ok ou se não há bugs :-).
Bom pessoal, agora o último passo… colocar o nosso app online com o shinyapps.io.
Publicando o app no shinyapps.io
É necessário criar uma conta no shinyapps.io. Vocês podem criar uma conta gratuitamente com um email e senha ou utilizar contas existentes do Google ou do Github.
O shinyapps vai solicitar um nome para a conta, que também será o domínio do app. Algumas restrições para o nome do domínio/conta: deve ter entre 4 e 63 caracteres, podendo ser letras, números e o símbolo - . O nome da conta não pode começar com números ou o símbolo -, e não podem terminar com o símbolo -.
Feito isso, vamos agora instalar o pacote rsconnect install.packages(“rsconnect”).
Agora precisamos fornecer a autorização para o pacote rsconnect fazer o deploy de nossos apps. Para isso:
-
Na página inicial do shinyapps.io, cliquem no botão superior direito referente à conta e cliquem em tokens.
-
Cliquem no botão show. A aplicação vai apresentar o comando que vocês precisam executar localmente no RStudio/R para habilitar o deploy dos apps com o rsconnect. Cliquem em Copy to clipboard e colem o comando no RStudio e executem. O comando deve ser semelhante ao código abaixo.
rsconnect::setAccountInfo(name='NOME-DA-MINHA-CONTA',
token='MEU-TOKEN-SUPER-HIPER-MEGA-SECRETO',
secret='SEGREDO-MAIS-SECRETO-DE-TODOS')
Se aparecer alguma mensagem de erro como:
Error: HTTP 401
GET https://api.shinyapps.io/v1/users/current/
bad signature
É porque o token ou o secret não foram copiados da forma correta.
Copiem manualmente o token e o secret, caso dê alguma mensagem de erro.
Se tudo ocorrer da forma prevista, não será exibido nenhum erro ou mensagem.
Se tudo funcionou, basta fazer o Deploy da aplicação. Tão simples como os comandos abaixo:
library(rsconnect)
deployApp()
O navegador padrão da sua máquina será aberto exibindo a aplicação online funcionando bonitinho :-). Deve ser semelhante com a imagem abaixo.
Se surgir algum erro estranho, é provável que a pasta não tenha as permissões adequadas. Para isso, use o comando abaixo no terminal do ubuntu
chmod -R 700 caminho/completo/do/diretório/com/o/app
O comando acima fornece permissão total para o usuário local no diretório indicado e subdiretórios.
É possível ter um controle do serviço responsável pelo app no shinyapps.io. Algumas das possibilidades:
-
É possível ter uma visão geral do app, como tempo online, acessos, datas de criação, atualização, tamanho da aplicação e outros.
-
Também é permitido analisar métricas computacionais da aplicação, como uso de memória, CPU, uso de rede e conexões simultâneas.
-
Na versão paga, é possível customizar a URL.
-
É possível ter acesso aos logs do app, sendo simples o processo de checar se ocorreram erros ao fazer o Deploy ou em runtime (tempo de execução).
Para mais detalhes, acessem https://shiny.rstudio.com/articles/shinyapps.html.
Considerações Finais
Bom pessoal, a ideia foi apresentar um passo a passo detalhado sobre o processo de desenvolvimento de um app na linguagem R com o shinyapps.io.
Abordei as fases de coleta dos dados, organização dos dados, persistência dos dados e pacotes em um arquivo, construção das lógicas da interface da aplicação e do servidor, um pouco de CSS para customizar o app e o processo de execução do app com shiny e submissão para o shinyapps.io de forma gratuita.
Espero que vocês tenham gostado do post e que ele tenha auxiliado vocês de alguma forma. Quaisquer dúvidas, podem deixar comentários logo abaixo :-)
Valeu !! Até o próximo post !! :-)