Investigando Programas de Pós-Graduação em Computação no Brasil
Resumo
Saudações pessoal.
A ideia deste post é compartilhar com vocês alguns códigos e resultados que gerei ao coletar, processar e analisar os dados dos Programas de Pós-Graduação em Computação do Brasil.
Metodologia
As seguintes ferramentas e linguagens foram utilizadas para a produção das análises e geração dos gráficos:
- R (R, 2019): Linguagem de Programação utilizada para Ciência de Dados. Em nosso caso, utilizada específicamente para as etapas de importação, organização, limpeza e visualização de dados;
- RStudio (RStudio, 2019): Ambiente de Programação Integrado para Ciência de Dados, de forma geral. Em nosso caso, foi o ambiente utilizado para programar as soluções com a linguagem R;
- Excel versão 2013 (Microsoft Excel, 2019): Programa de planilhas eletrônicas para armazenamento, manipulação e visualização de dados;
- Github (Github, 2019): Plataforma com comunidades de desenvolvedores para descoberta, compartilhamento e criação de códigos e soluções de software com controle de versão. O Github foi utilizado para compartilhar o código utilizado neste tutorial para garantir a reprodutibilidade dos experimentos e isenção na realização das análises dos dados. Os códigos do projeto podem ser acessados neste link.
Sobre os dados coletados
Inicialmente, os dados dos Programas de Pós-Graduação em Computação foram extraídos de um arquivo em PDF, obtido neste link. Abaixo, é apresentada a forma que os dados estavam armazenados no PDF.
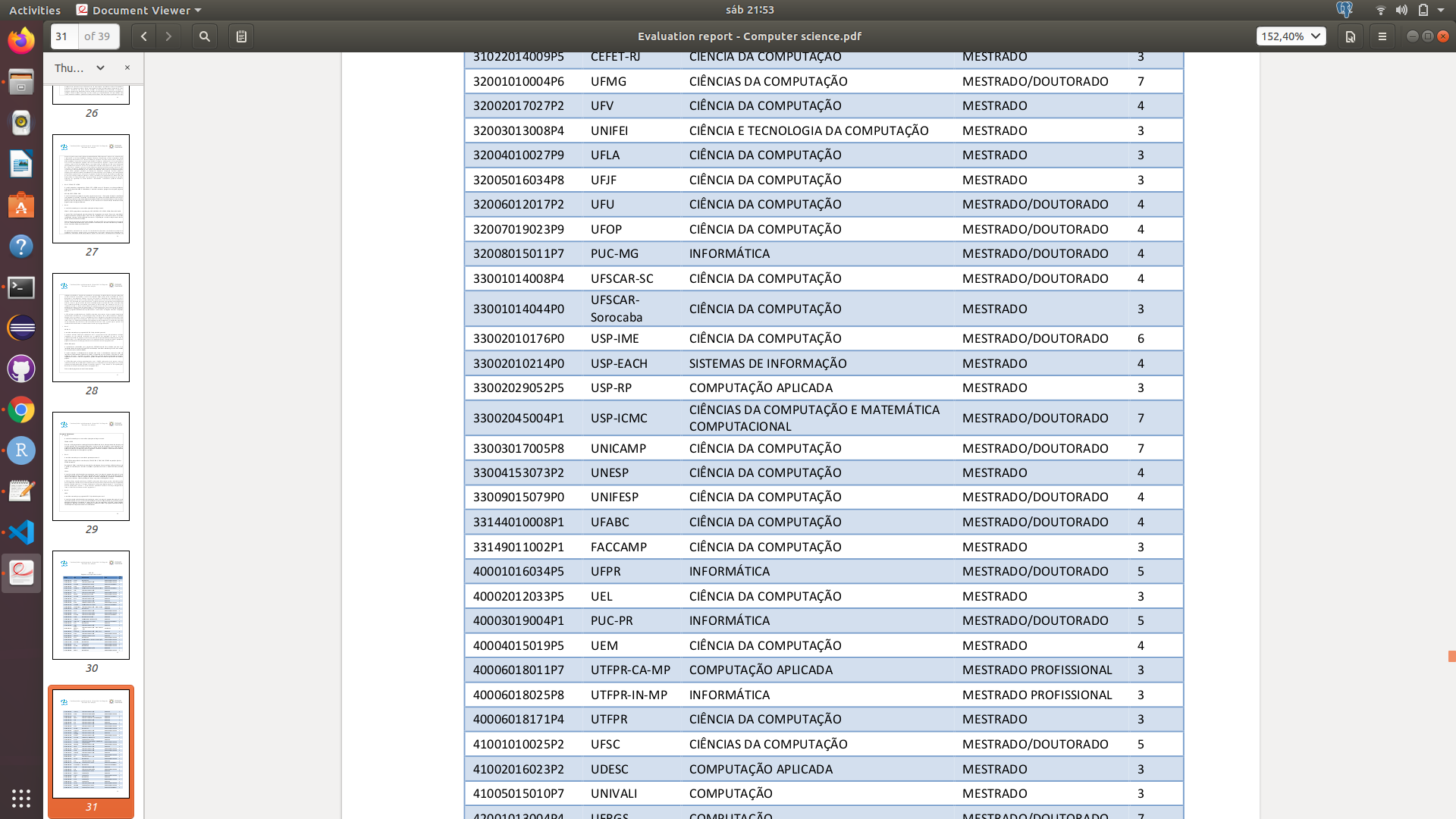
Eu tinha como objetivo gerar um vídeo e apresentar a metodologia de como se extrair dados de arquivos em PDF e gerar análises visuais destes dados, e como estudo de caso, os dados dos Programas de Computação.
Olhem só como ficou o script para realizar a extração do PDF para uma planilha excel… Para entender em detalhes a sequência lógica dos comandos e metodologia adotada, acessem meu Github -> Lubrum).
if (!require(pdftools)) install.packages("pdftools", repos = "http://cran.us.r-project.org")
require(pdftools)
if (!require(dplyr)) install.packages("dplyr", repos = "http://cran.us.r-project.org")
require(dplyr)
if (!require(readr)) install.packages("readr", repos = "http://cran.us.r-project.org")
require(readr)
if (!require(stringi)) install.packages("stringi", repos = "http://cran.us.r-project.org")
require(stringi)
if (!require(stringr)) install.packages("stringr", repos = "http://cran.us.r-project.org")
require(stringr)
if (!require(xlsx)) install.packages("xlsx", repos = "http://cran.us.r-project.org")
require(xlsx)
file_pdf <- pdf_text("../pdf/Evaluation report - Computer science.pdf") %>% read_lines()
file_pdf <- file_pdf[1098:1190]
file_pdf <- file_pdf[-(grep("Coordenação", file_pdf))]
file_pdf <- file_pdf[-(grep("Diretoria", file_pdf))]
file_pdf <- file_pdf[-(24:28)] #Remove UFBA-UNIFACS-UEFS
file_pdf <- file_pdf[-(34:35)] #Remove some useless info
file_pdf <- file_pdf[-(75:76)] #Remove some useless info
file_pdf <- file_pdf[-(44:46)] #Remove UFSCAR-Sorocaba
file_pdf <- file_pdf[-(47:49)] #Remove USP-ICMC
file_pdf[56]<-gsub("-CA-MP"," ",file_pdf[56])
file_pdf[57]<-gsub("-IN-MP"," ",file_pdf[57])
file_pdf <- strsplit(file_pdf, " ")
list_pdf <- 0
a <- 1
for(i in 1:length(file_pdf)){
info_number <- length(file_pdf[[i]][!stri_isempty(file_pdf[[i]])])
for(j in 1:info_number){
list_pdf[a] <- str_trim(file_pdf[[i]][!stri_isempty(file_pdf[[i]])][j])
a <- a + 1
}
}
data_pdf <- data.frame(stringsAsFactors = FALSE, "Universidade" = 0, "Curso" = 0, "Nivel" = 0, "Nota" = 0)
a <- 1
for(i in seq(from = 2, to = length(list_pdf), by = 5)){
data_pdf[a,1] <- list_pdf[i]
data_pdf[a,2] <- list_pdf[i+1]
data_pdf[a,3] <- list_pdf[i+2]
data_pdf[a,4] <- list_pdf[i+3]
a <- a + 1
}
write.xlsx(data_pdf, file = "../pdf/universities_before.xlsx", col.names = TRUE, row.names = TRUE, append = FALSE)
Porém, descobri posteriormente sobre a existência do site Sucupira. O Sucupira possui os dados de todos os Programas de Pós-Graduação do Brasil. Abaixo, uma foto da página dos Programas de Pós em Computação do Brasil. É possível clicar em cada um dos Programas e obter informações mais específicas de cada um.
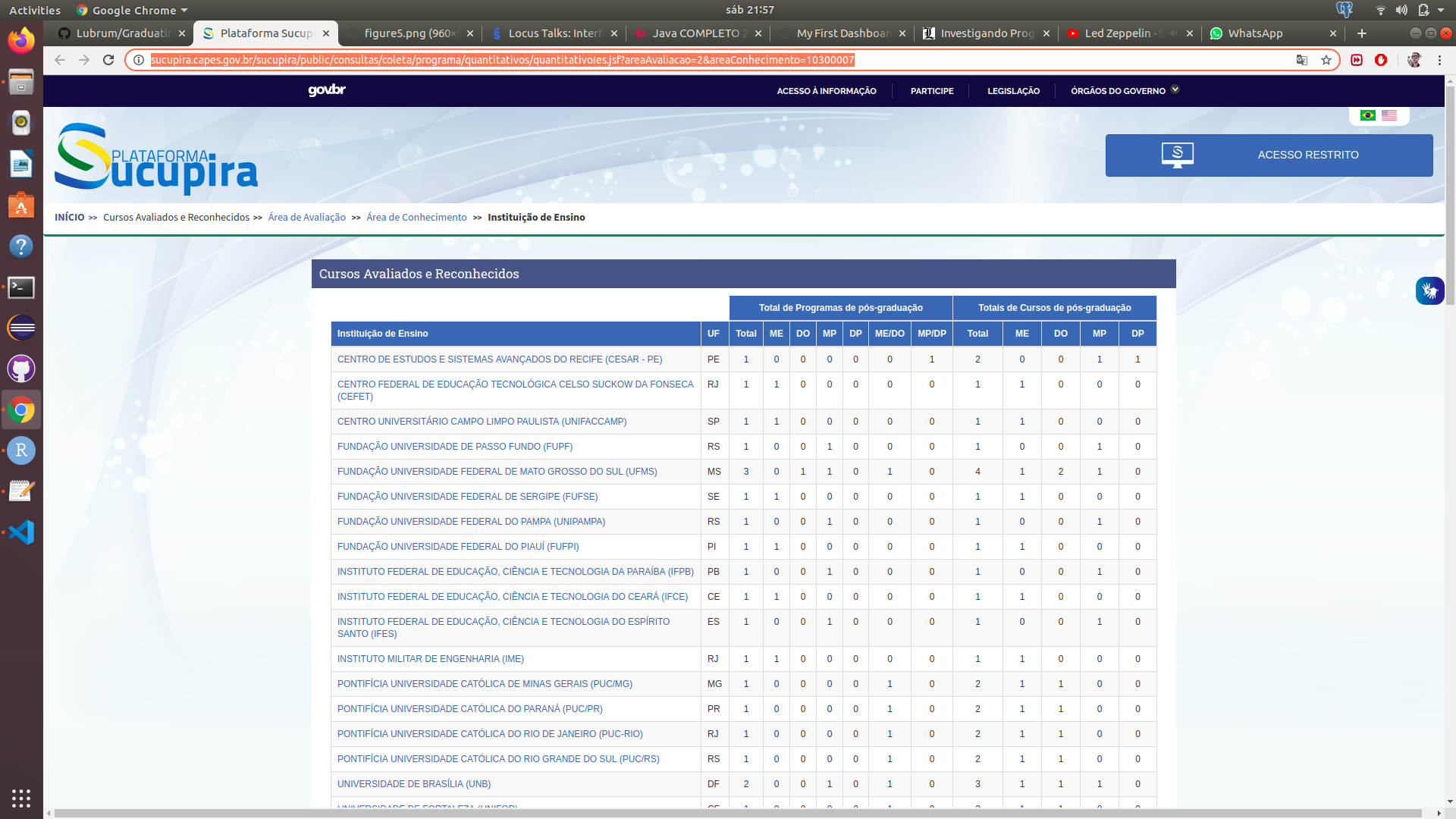
Então decidi expandir o horizonte dos meus objetivos. Primeiro realizei a metodologia de extração dos dados do PDF, e na sequência realizei uma validação e integração com os dados da plataforma Sucupira. O processo de integração e validação foi manual, conferindo caso a caso, entre os dados do PDF e os do Sucupira. Dados faltantes foram inseridos na base de dados, que no momento eram planilhas eletrônicas (Excel).
Posteriormente, pensei: já que estou coletando dados dos Programas, por que não coletar informações sobre as linhas de pesquisa, áreas de concentração e temas de pesquisa? Então manualmente acessei o site de cada um dos Programas e gerei uma base de dados com essas informações, também armazenadas em planilhas eletrônicas (Excel).
O resultado deste processo pode ser conferido abaixo.
Também foram geradas outras planilhas com dados de área de concentração, linhas de pesquisa, temas de pesquisa e nível do Programa.
Resultados
Com os dados consolidados, foi necessário apenas importar, integrar e visualizar os mesmos. Segue abaixo parte do código para a integração dos dados (sem a importação das bibliotecas) e geração do primeiro mapa com algumas informações dos Programas :D.
O shapefile dos mapas pode ser obtido aqui e os dados das cidades e estados do Brasil no Github do kelvins.
# reading data from csv
universities_path <- "../csv/universities_after.xlsx"
cities_path <- "../csv/brazilian_cities.csv"
states_path <- "../csv/brazilian_states.csv"
research_names_path <- "../csv/research_names.xlsx"
university_research_path <- "../csv/university_research.xlsx"
graduation_level_path <- "../csv/graduation_level.xlsx"
course_name_path <- "../csv/course_name.xlsx"
concentration_area_path <- "../csv/concentration_area.xlsx"
university_concentration_area_path <- "../csv/university_concentration_area.xlsx"
universities <- read.xlsx(universities_path, sheetIndex = 1, encoding = "UTF-8")
cities <- read.csv(cities_path, sep = ",", stringsAsFactors = FALSE, encoding = "UTF-8")
states <- read.csv(states_path, sep = ",", stringsAsFactors = FALSE, encoding = "UTF-8")
research_names <- read.xlsx(research_names_path, sheetIndex = 1, encoding = "UTF-8")
university_research <- read.xlsx(university_research_path, sheetIndex = 1, encoding = "UTF-8")
graduation_level <- read.xlsx(graduation_level_path, sheetIndex = 1, encoding = "UTF-8")
course_name <- read.xlsx(course_name_path, sheetIndex = 1, encoding = "UTF-8")
concentration_area <- read.xlsx(concentration_area_path, sheetIndex = 1, encoding = "UTF-8")
university_concentration_area <- read.xlsx(university_concentration_area_path, sheetIndex = 1, encoding = "UTF-8")
# reading data from shapefile
shape_brazil_path <- "../shapefile/Brazil.shp"
shape_brazil <- readOGR(shape_brazil_path, "Brazil", encoding = "latin1")
# joining data into one dataframe
all_data <- universities %>% left_join(cities, by = c("city_id" = "ibge_code"))
all_data <- all_data %>% left_join(states, by = c("state_id" = "state_id"))
all_data <- all_data %>% left_join(university_research, by = c("id" = "university_id"))
all_data <- all_data %>% left_join(research_names, by = c("research_id" = "id"))
all_data <- all_data %>% left_join(graduation_level, by = c("level" = "id"))
all_data <- all_data %>% left_join(course_name, by = c("course" = "id"))
all_data <- all_data %>% left_join(university_concentration_area, by = c("id" = "university_id"))
all_data <- all_data %>% left_join(concentration_area, by = c("concentration_area_id" = "id"))
# cleaning and preparing data
all_data <- all_data[,-9]
all_data <- all_data[,-14]
all_data <- all_data[,-16]
all_data <- all_data[,-19]
all_data$latitude <- as.numeric(as.character(all_data$latitude))
all_data$longitude <- as.numeric(as.character(all_data$longitude))
all_data$grade <- as.numeric(as.character(all_data$grade))
# possible values for CAPES concept
mybreaks <- as.numeric(c(3, 4, 5, 6, 7))
# black theme
theme <- theme(axis.text = element_text(size = 16),
plot.caption = element_text(size = 12, face = "bold", color = "white"),
axis.title = element_text(size = 18, face = "bold", color = "white"),
legend.title = element_text(size = 18, color = "white"),
legend.text = element_text(size = 14, color = "white"),
legend.key.width = unit(0.4, "cm"),
legend.position = c(.95, .25),
legend.key.size = unit(0.8, "cm"),
legend.box.background = element_rect(color = "white", size = 0.5),
legend.justification = c("right", "top"),
legend.box.just = "right",
legend.margin = margin(6, 6, 6, 6)
text = element_text(color = "white"),
legend.background = element_rect(fill = "black"),
panel.background = element_rect(fill = "black"),
plot.title = element_text(size = 19, hjust = 0.5, color = "white"),
panel.grid.minor.y = element_line(size =.1, color = "grey"),
panel.grid.minor.x = element_line(size =.1, color = "grey"),
panel.grid.major.y = element_line(size =.1, color = "grey"),
panel.grid.major.x = element_line(size =.1, color = "grey"),
plot.background = element_rect(fill = "black"),
axis.text.x = element_text(color = "white"),
axis.text.y = element_text(color = "white"),
axis.title.x = element_text(color = "white"),
axis.title.y = element_text(color = "white"))
labs <- labs(x = "Longitude", y = "Latitude", caption = "Fonte: Programas de Pós-Graduação em Computação - Plataforma Sucupira.")
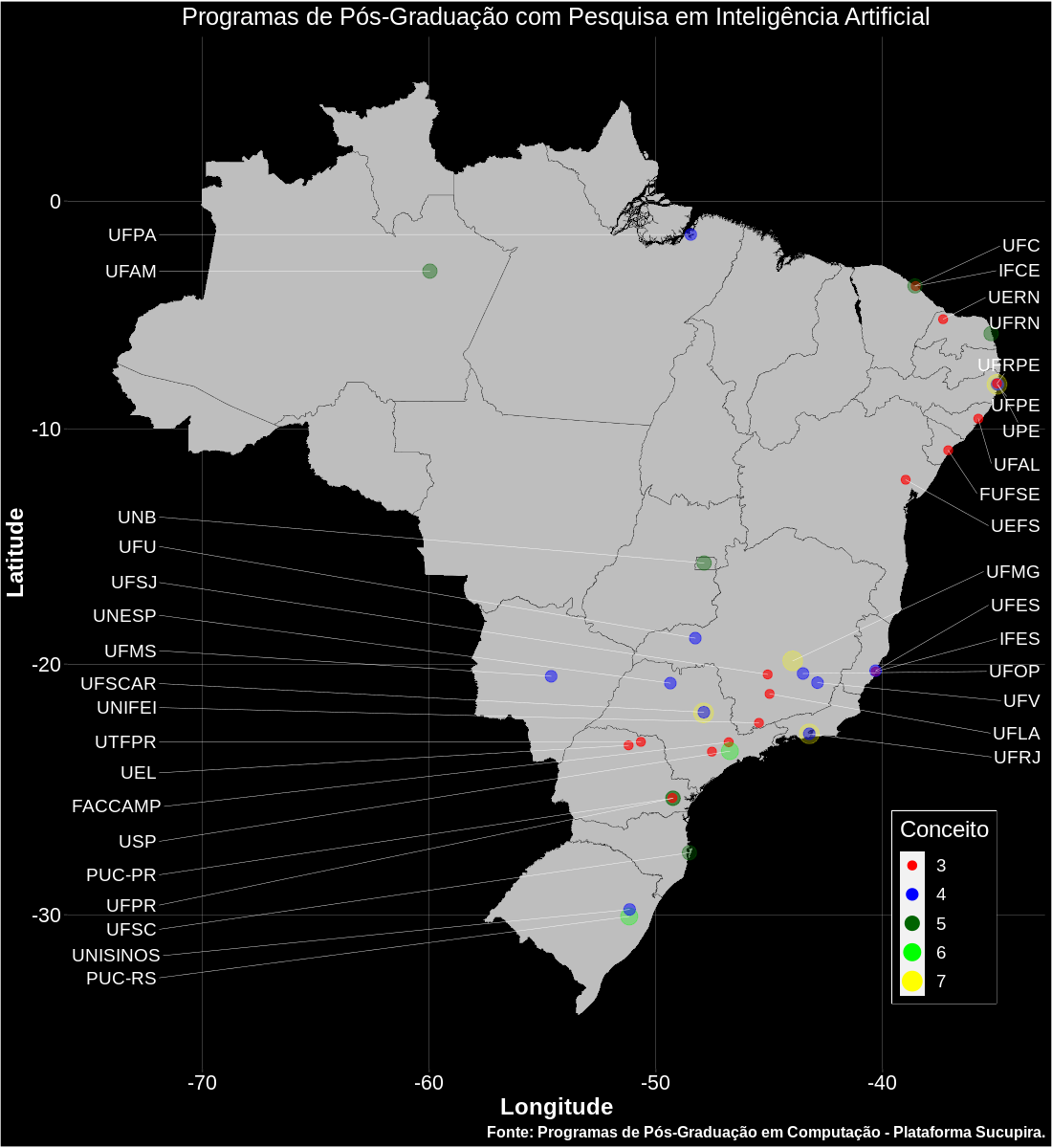
all_data_2 <- subset(all_data, all_data$research_name == "Inteligencia Artificial")
ggplot() +
geom_polygon(data = shape_brazil, aes(x = long, y = lat, group = group), fill = "grey", size = 0.1, color = "black") +
geom_point(data = all_data_2[!duplicated(all_data_2$id),], aes(x = longitude, y = latitude, size = as.factor(grade), color = as.factor(grade), alpha = I(2/grade))) +
scale_colour_manual(name = "Conceito", values = c("red","blue","dark green","green","yellow")) +
scale_size_manual(name = "Conceito", values = mybreaks) +
geom_text_repel(data = all_data_2[all_data_2$longitude > -45 & !duplicated(all_data_2$code),], aes(x = longitude, y = latitude, label = code, size = as.factor(5)), hjust = 0, nudge_x = -34 - subset(all_data_2, all_data_2$longitude > -45 & !duplicated(all_data_2$code))$longitude, direction = "y", show.legend = FALSE, color = "white", segment.color = "white", segment.size = 0.15) +
geom_text_repel(data = all_data_2[all_data_2$longitude <= -45 & !duplicated(all_data_2$code),], aes(x = longitude, y = latitude, label = code, size = as.factor(5)), hjust = 1, nudge_x = -72 - subset(all_data_2, all_data_2$longitude <= -45 & !duplicated(all_data_2$code))$longitude, direction = "y", show.legend = FALSE, color = "white", segment.color = "white", segment.size = 0.15) +
coord_map() +
guides() +
ggtitle("Programas de Pós-Graduação com Pesquisa em Inteligência Artificial") +
labs + theme
Também é possível gerar gifs como a apresentada abaixo, mostrando o surgimento dos Programas com o passar dos anos no Brasil.
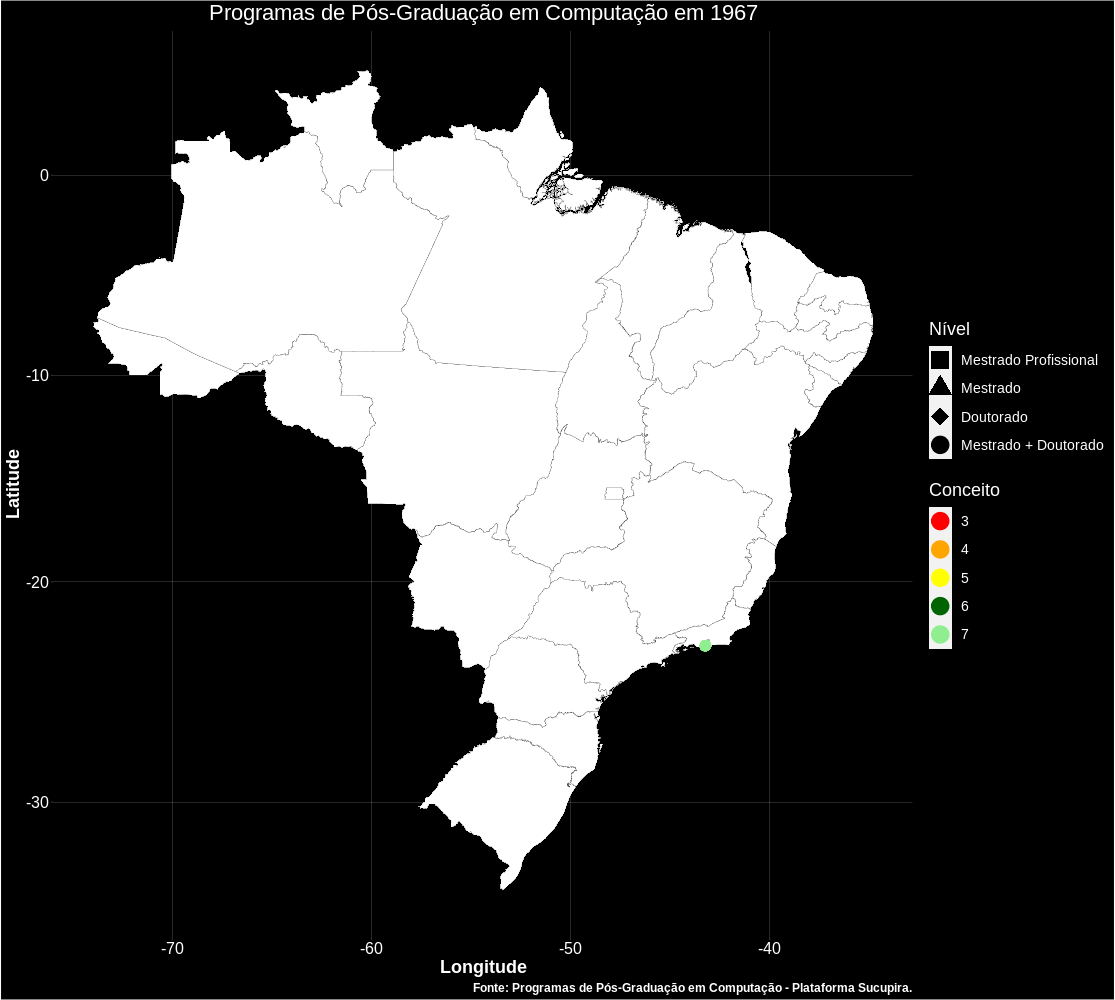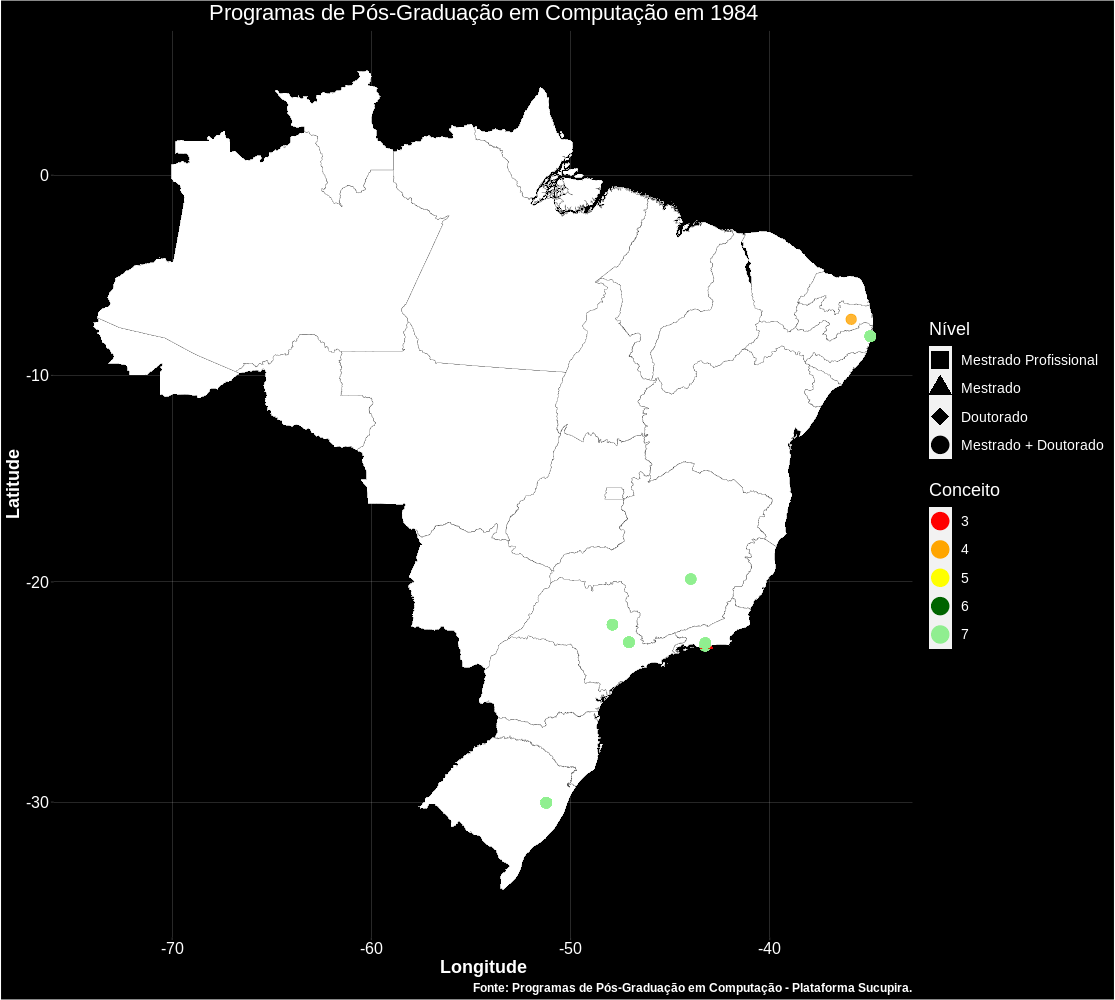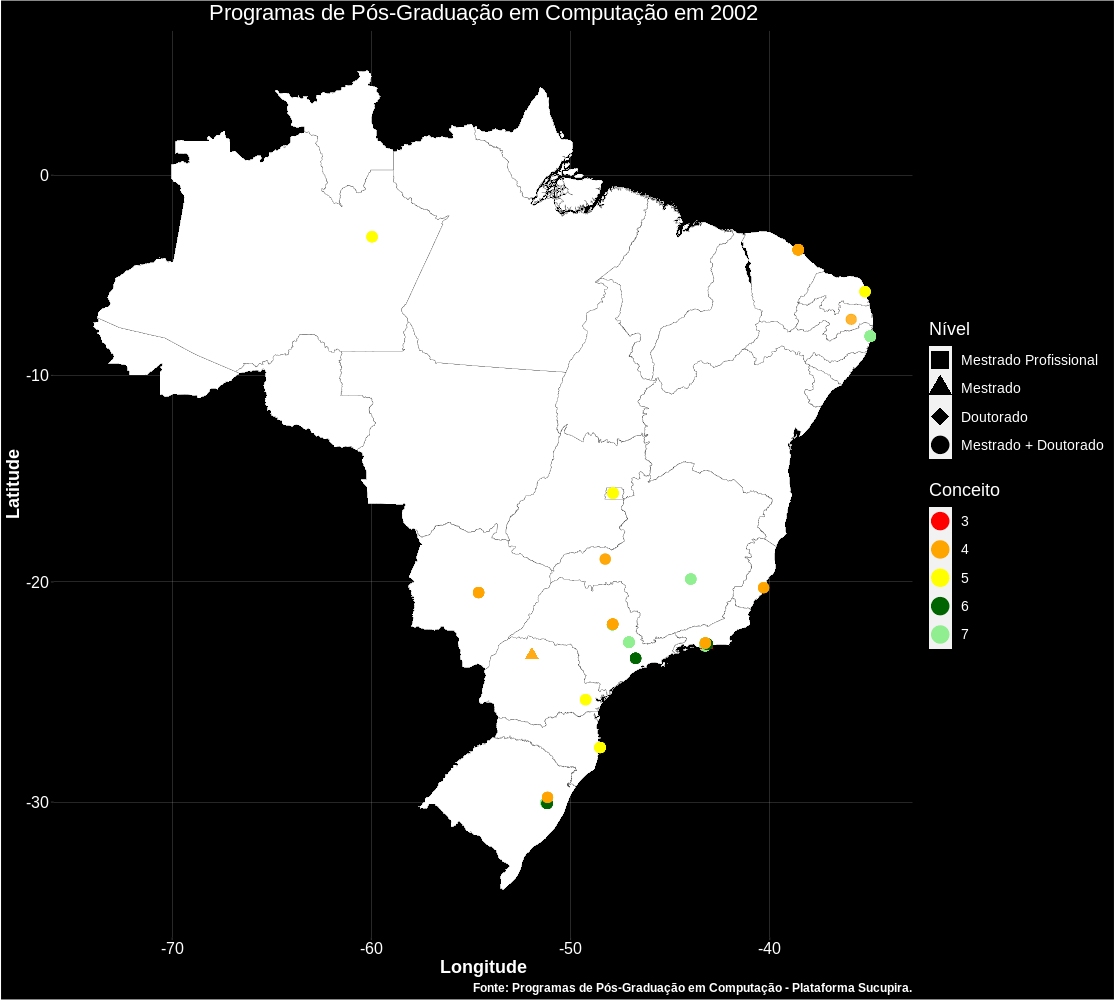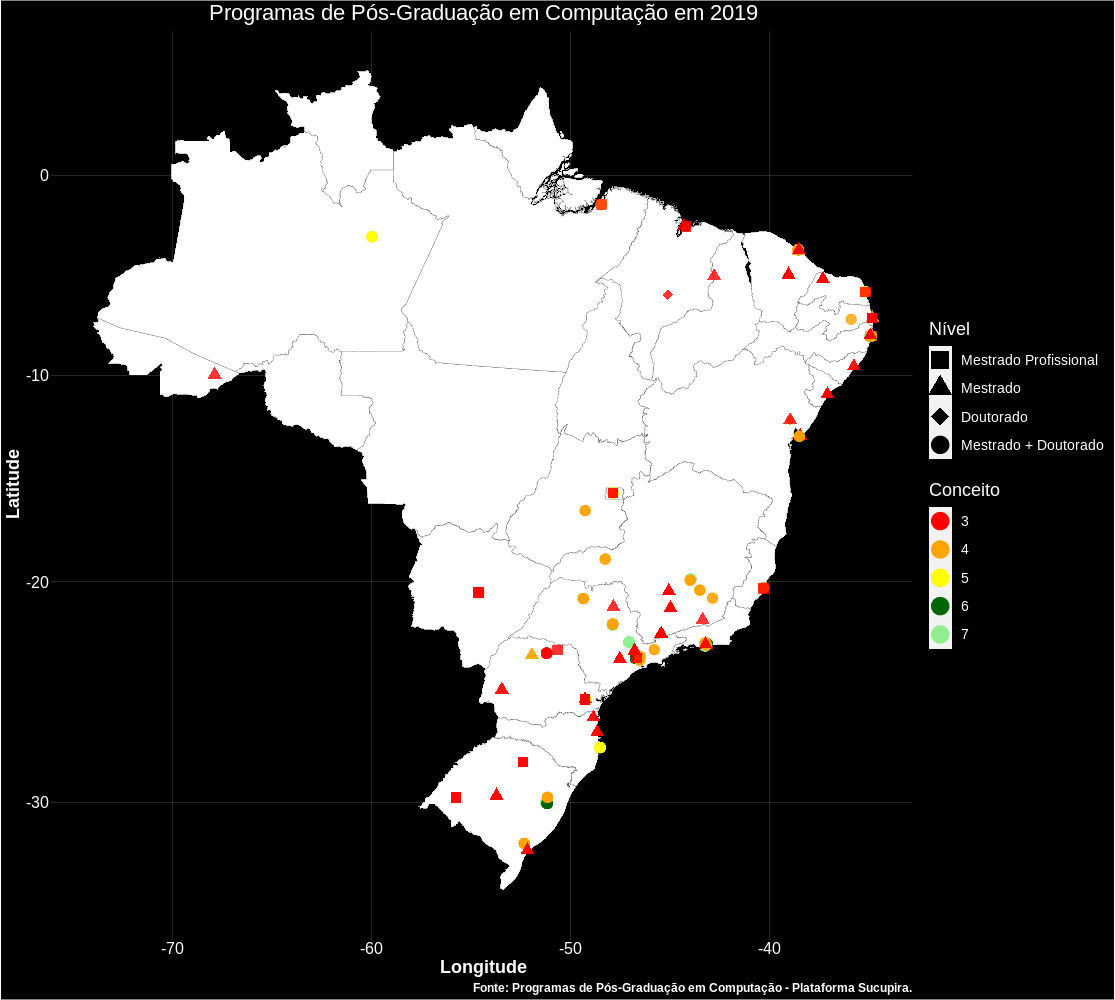
Próximos passos
No momento é possível fazer os seguintes filtros por Programa de Pós-Graduação em Computação:
- Programas por conceito da CAPES;
- Programas por região geográfica (cidade ou estado);
- Programas por nível de Pós (Mestrado, Doutorado ou Mestrado Profissional);
- Programas por área de concentração;
- Programas por tema de pesquisa;
- Programas por ano ou período de criação;
A ideia para a sequência do projeto, além de compartilhar estes dados e informações, é criar uma maneira de disponibilizar essas informações em uma solução online, com interface amigável com o usuário, para o mesmo selecionar os filtros e dados/informações de seu interesse. Uma ferramenta direcionada para graduados com interesse no ingresso na Pós-Graduação. Também há a possibilidade de agregar mais informações por Programa, como dados dos pesquisadores, alunos e respectivas publicações. Para esta última proposta, precisarei do auxílio da comunidade para esta etapa, pois são MUITOS dados para serem coletados, integrados, e mantidos. O projeto inteiro está em meu Github, e quem tiver interesse em colaborar com o projeto, é só entrar em contato!! :-)
Considerações Finais
Bom pessoal, então era isso.
Quis trazer para vocês um pouco de ideias, códigos e resultados, com base em um problema que enfrentei em um ponto da minha vida, e muitos meses depois vislumbrei essa possibilidade de solução. Compartilhei a ideia com vocês, agora é colocar a mão na massa e dar a sequência.
Para os interessados em contribuir, servirá como experiência prática com o R e tecnologias web, processamento e análise de dados, estatística, visualização de dados, um pouco de Git e talvez outras tecnologias não vislumbradas no momento. Também é possível agregar a participação de vocês neste projeto nos seus próprios portfólios pessoais, para apresentar no currículo ou em entrevistas de emprego. Enfim, muito bônus mas também respectivo ônus.
Obrigado e até o próximo post !!
Referências Bibliográficas
Github. Built for developers. Acesso em: 08 set. 2019.
Microsoft Excel. Excel. Acesso em: 08 set. 2019.
R. The R Project for Statistical Computing. Acesso em: 08 set. 2019.