Resumo
Saudações pessoal.
A ideia deste post é compartilhar com vocês um exemplo completo de Análise Exploratória de Dados (em inglês é EDA - Exploratory Data Analysis). Também são aplicadas técnicas estatísticas como testes de normalidade, análise de variância, kruskal wallis e outros.
Este trabalho foi desenvolvido no Sistema Operacional Ubuntu versão 18.10 LTS 64 bits, com o auxílio da linguagem R v.3.6.3 (2020-02-29) e do RStudio v. 1.2.5033.
Tópicos
Parte I - Fonte dos dados
Os dados utilizados como base para este trabalho são os de estudantes de disciplinas de Desenho Técnico de uma IES (Instituição de Ensino Superior), e podem ser obtidos pelo meu Github.
Dois datasets foram fornecidos:
1 - Dados de estudantes separados por curso de graduação, de todos professores que ministraram a disciplina (sem informação credencial de estudantes e sem identificação de professores).
2 - Dados de estudantes da turma de um professor específico da disciplina.
Vamos fazer a EDA e análises estatísticas do primeiro dataset neste post.
Parte II - Análise Exploratória de Dados do Dataset
Temos 16 variáveis (ou colunas) por aluno:
- Nome do aluno;
- Identidade estudantil (matrícula);
- Código do curso;
- Ano;
- Semestre;
- Código de disciplina;
- Nome da disciplina;
- Número de créditos (1 crédito = 15 horas);
- Nota final;
- Situação do aluno;
- Carga horária total em horas;
- Tipo de Admissão na Universidade;
- Ano de admissão;
- Tipo de evasão (incluindo alunos matriculados);
- Ano de evasão (se aplicável);
- Sexo;
Todas as informações sensíveis dos conjuntos de dados foram removidas antes de iniciar essa análise, como os nomes dos alunos. A identificação dos alunos foi criptografada para preservar os dados sensíveis da universidade.
Inicialmente, vamos importar os pacotes necessários para a execução de nossas análises.
| |
Inicialmente, vamos importar os dados de cada uma das planilhas com dados.
| |
O que significa cada Sigla?
- BAEE: Bacharelado em Engenharia de Energias Renováveis e Ambiente;
- BAEA: Bacharelado em Engenharia de Alimentos;
- BAEC: Bacharelado em Engenharia de Computação;
- BAEP: Bacharelado em Engenharia de Produção;
- BAEQ: Bacharelado em Engenharia Química;
- BALF: Licenciatura em Física;
Com os dados importados e organizados em dataframes, podemos observar que o dataframe BAEA possui uma coluna de informações a mais. É possível verificar com uma rápida visualização no RStudio, no Global Environment. Como a informação não possui contexto que agregue em nossas análises, vamos removê-la.
| |
Vamos checar o nome das colunas de cada dataframe, para confirmar se são as mesmas informações.
| |
BAEC possui um nome diferente na coluna de carga horária, então vamos deixar o nome igual ao dos outros dataframes.
| |
Agora podemos concatenar todos os dados com o comando rbind. Todos os dados estão agora no dataframe all_data. A concanetação com rbind é feita pelas linhas.
| |
Também vamos reduzir o nome de algumas colunas para facilitar o desenvolvimento na sequência.
| |
Feita a junção dos dados, vamos analisar individualmente o conteúdo único das colunas que contém categorias (Strings). Também vamos verificar em cada coluna se existem NaNs (Not a Number - Não-Números) ou campos vazios.
| |
Olhem só, existe uma porção dos dados em que a nota na média final está com um valor incorreto e constante de 100000. Vamos transformar em 0 e remover os registros posteriormente.
| |
Mais dados inconsistentes. O ano de evasão registrado como NA (Not Available - Não disponível) em muitos registros, provavelmente indicando casos de alunos que não evadiram da universidade. Vamos transformar em zeros.
| |
Agora vamos descartar casos de alunos nas seguintes situações:
- Dispensados sem nota (todos neste caso ficaram com média zero);
- Trancamento Parcial (todos neste caso ficaram com média zero);
- Matrícula (alunos atualmente matrículados não têm informação sobre a média final);
- Disciplina Não Concluída (todos neste caso ficaram com média zero);
- Aproveitamento em casos que a média foi 0;
Como vamos posteriormente utilizar tratamentos estatísticos, temos que ter o cuidado de não deixar a amostra viesada por causa de registros sem significância para a análise. Os casos acima citados são excepcionais e não vão agregar resultados para este trabalho de análise das médias finais dos alunos. Isso não significa, porém, que tais dados não tenham utilidade. Tais dados podem ser usados para descobrir, por exemplo, o número médio de reprovações de alunos de Desenho Técnico que desistem dos cursos, ou que se formam. Isso pode ser feito através da matrícula de cada aluno. Porém, não é o nosso escopo agora. :-)
Os alunos aprovados e reprovados por nota ou frequência possuem a informação valiosa para as nossas análises.
Vamos também aproveitar para dar um nome mais conciso para algumas formas de evasão.
| |
Agora que temos nosso conjunto de dados tratado e integrado em um único dataframe, vamos iniciar as análises gerando diversas estatísticas sobre esses dados. Para isso, vamos reutilizar a função abaixo:
| |
Na sequência, vamos observar os resultados para cada agregação possível dos nossos dados.
| |
Observando o primeiro caso (média, mediana, desvio padrão, mínimo, máximo, n° de amostras, 1° e 3° quartis e IQR (Interquartil Range - Distância Interquartil) dos dados agrupados por curso de graduação), percebemos que a melhor média e menor desvio padrão é do BAEQ, enquanto que a pior média e alto valor de desvio é do BALF. Por outro lado, BALF tem 1/10 das amostras de BAEQ, evidenciando que o resultado discrepante em BALF pode ser devido ao número de amostras. Cabe ressaltar que neste conjunto estão incluídos alunos aprovados, reprovados por nota e frequência (que a nota sempre fica em zero). Os outros cursos aparentemente possuem as médias mais próximas uns dos outros.
Tudo bem. Analisamos um caso. Porém temos outros numerosos casos. Podemos salvar esses dados das tabelas em planilhas para uso e analises posteriores.
Vamos tirar proveito do poder dos gráficos do R para verificarmos visualmente esses resultados.
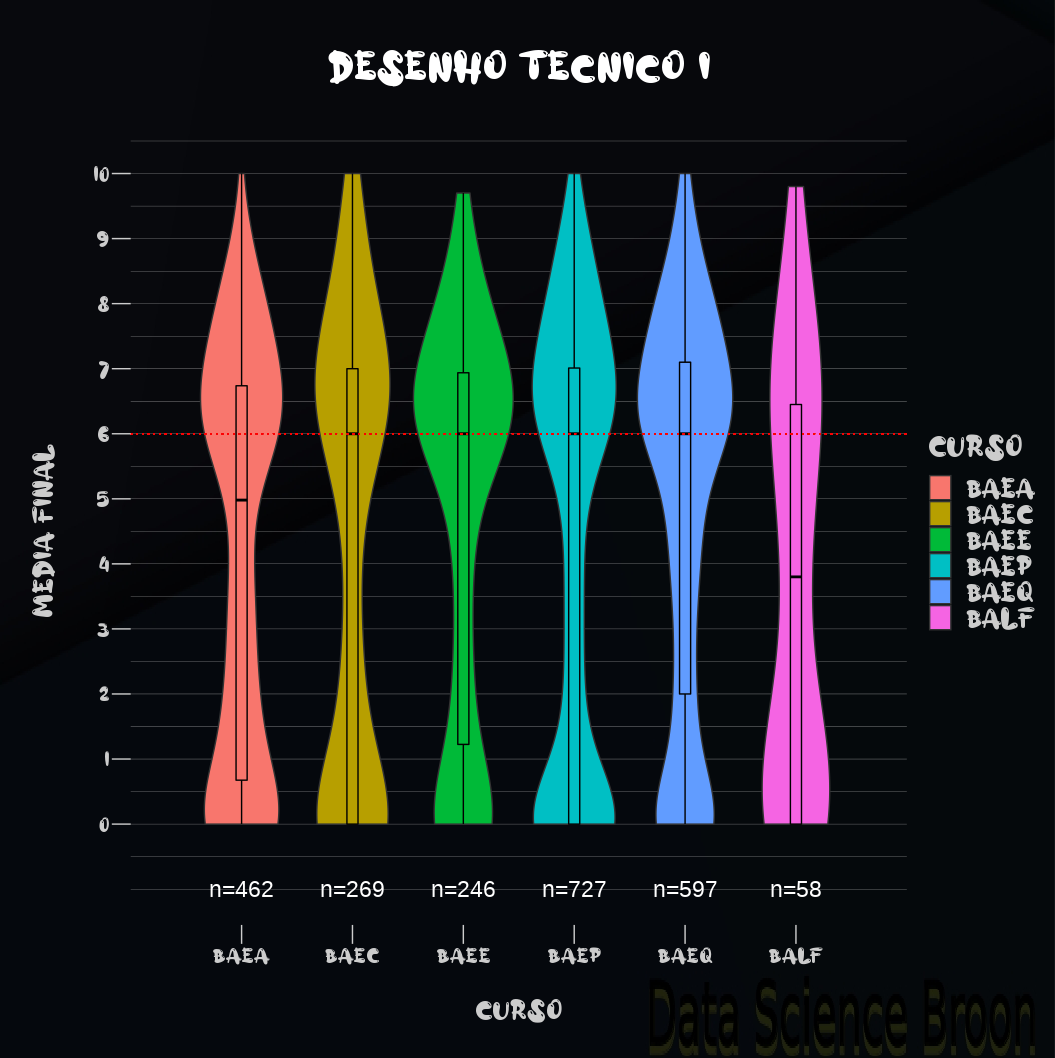
Podemos confirmar o que foi dito anteriormente através deste gráfico. Se você não sabe como interpretar um boxplot, eu sugiro este link, que explica em detalhes cada um dos componentes do boxplot.
Vamos verificar outros casos.
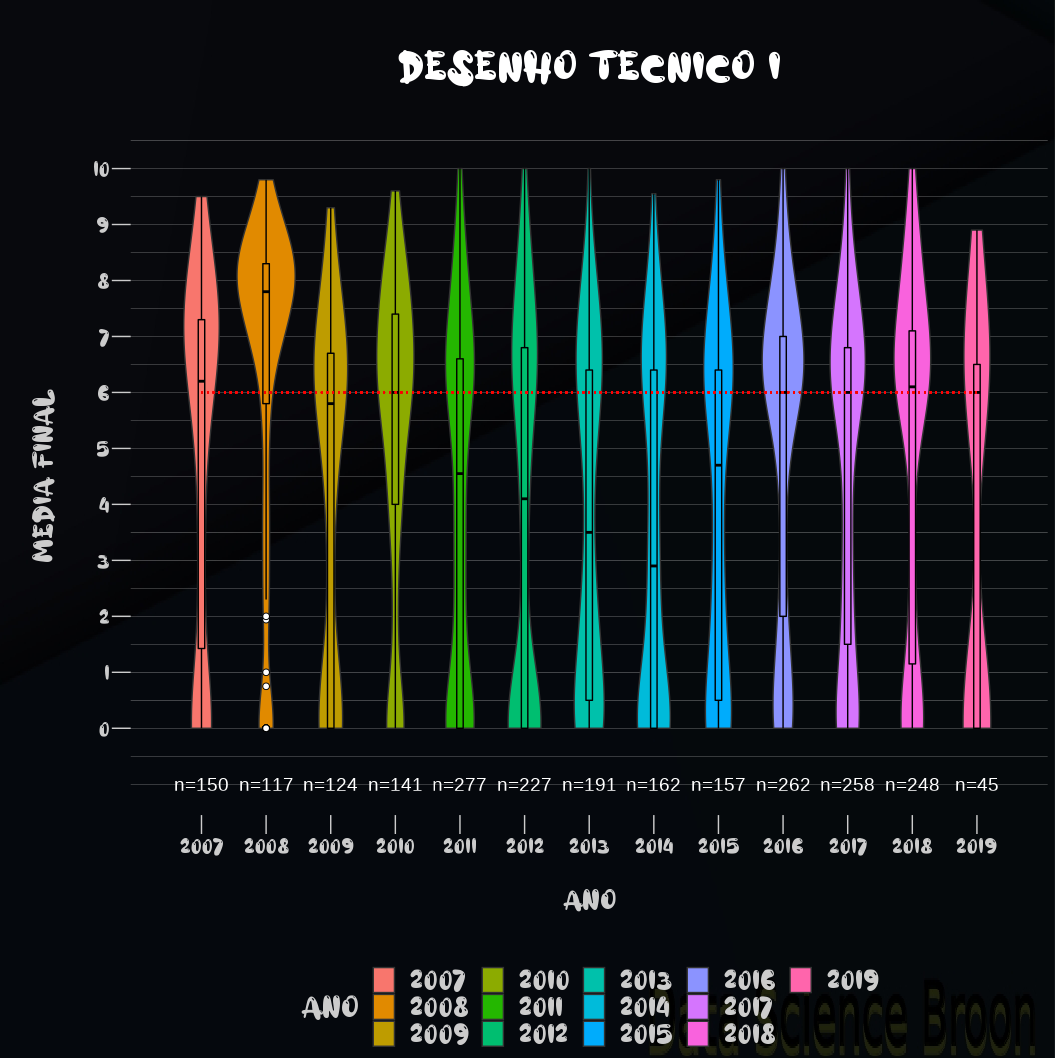
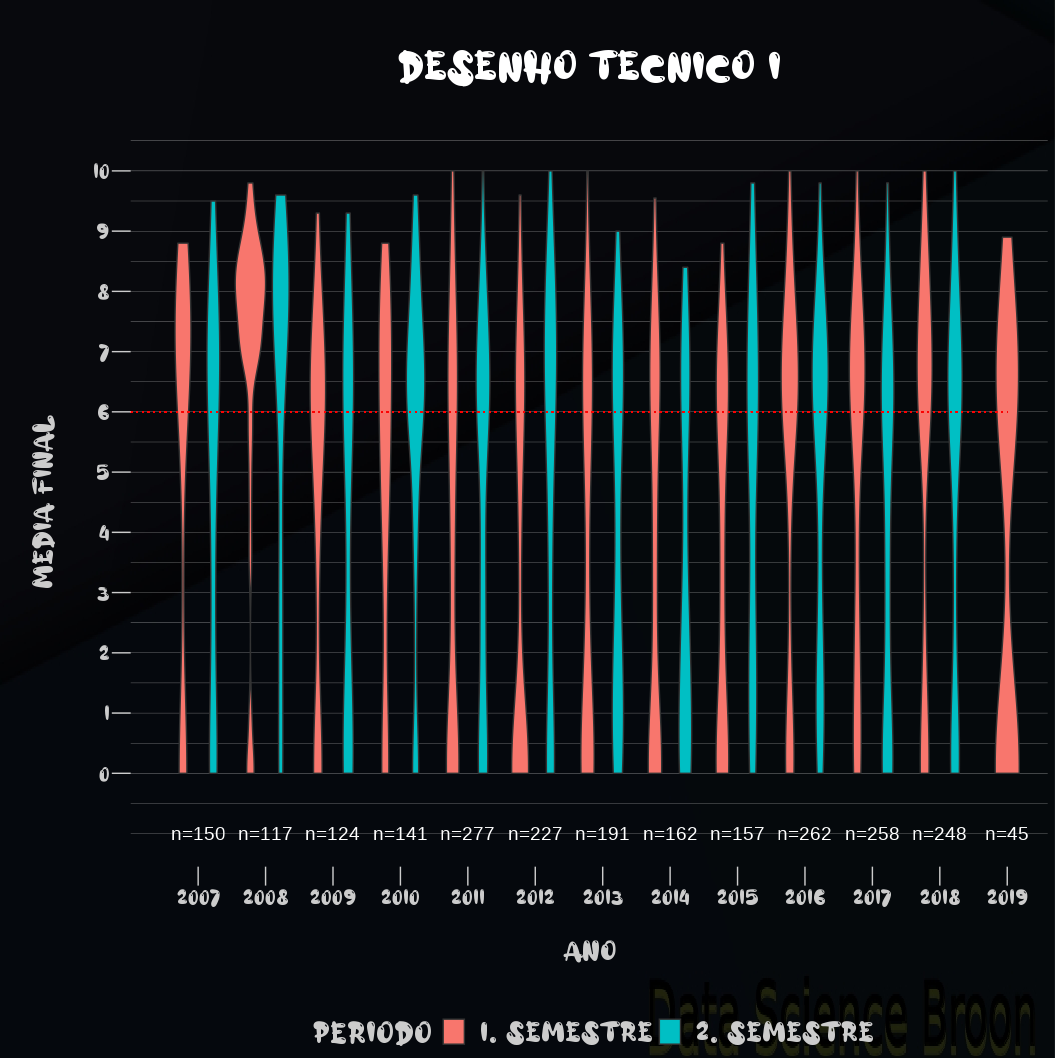
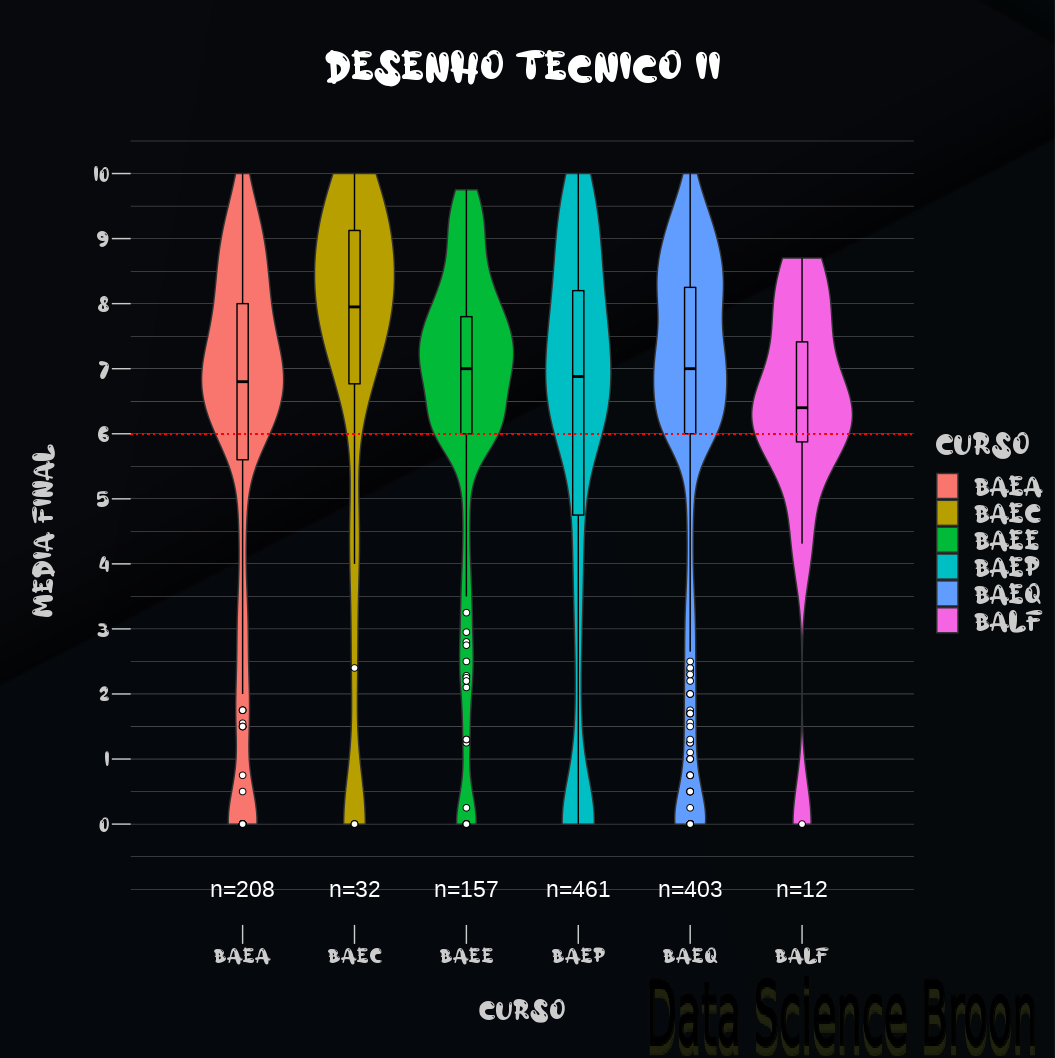
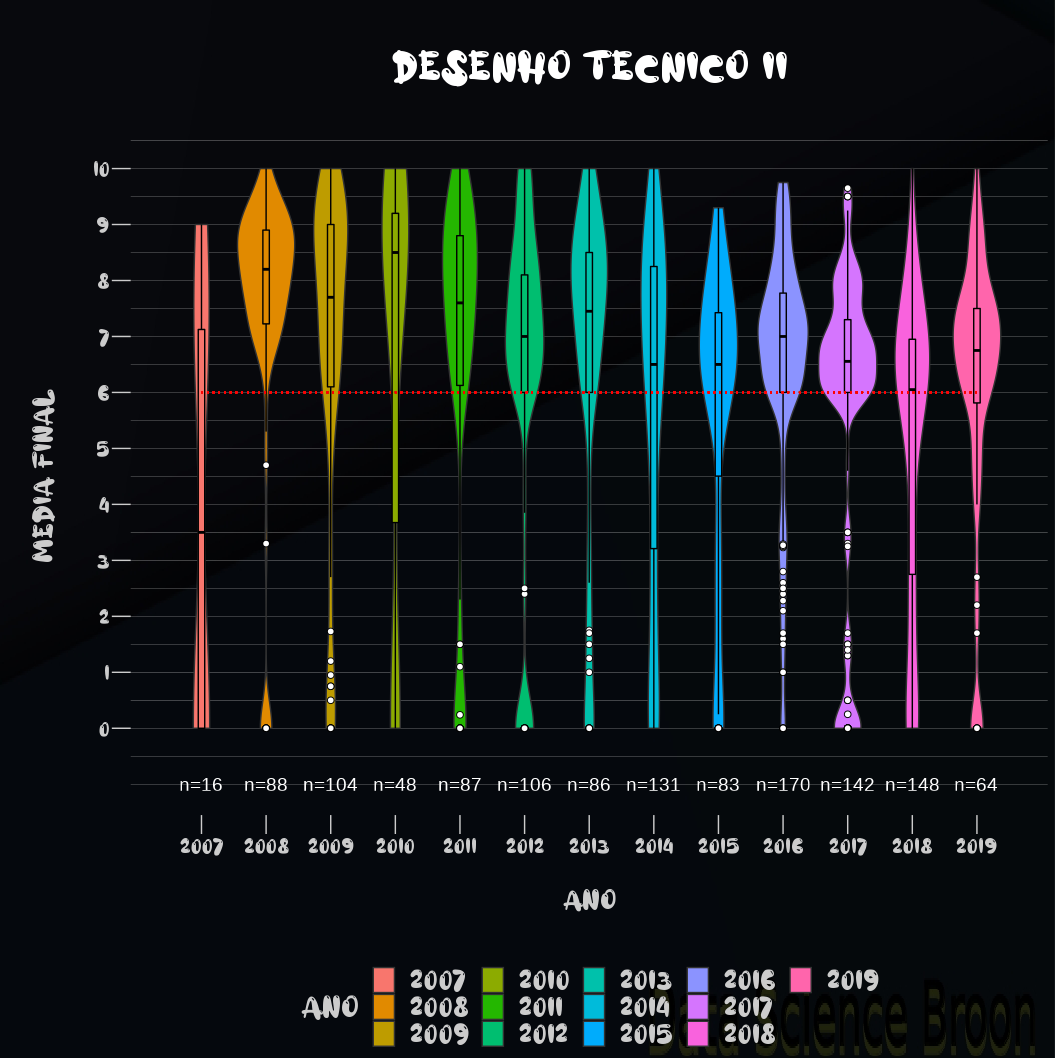
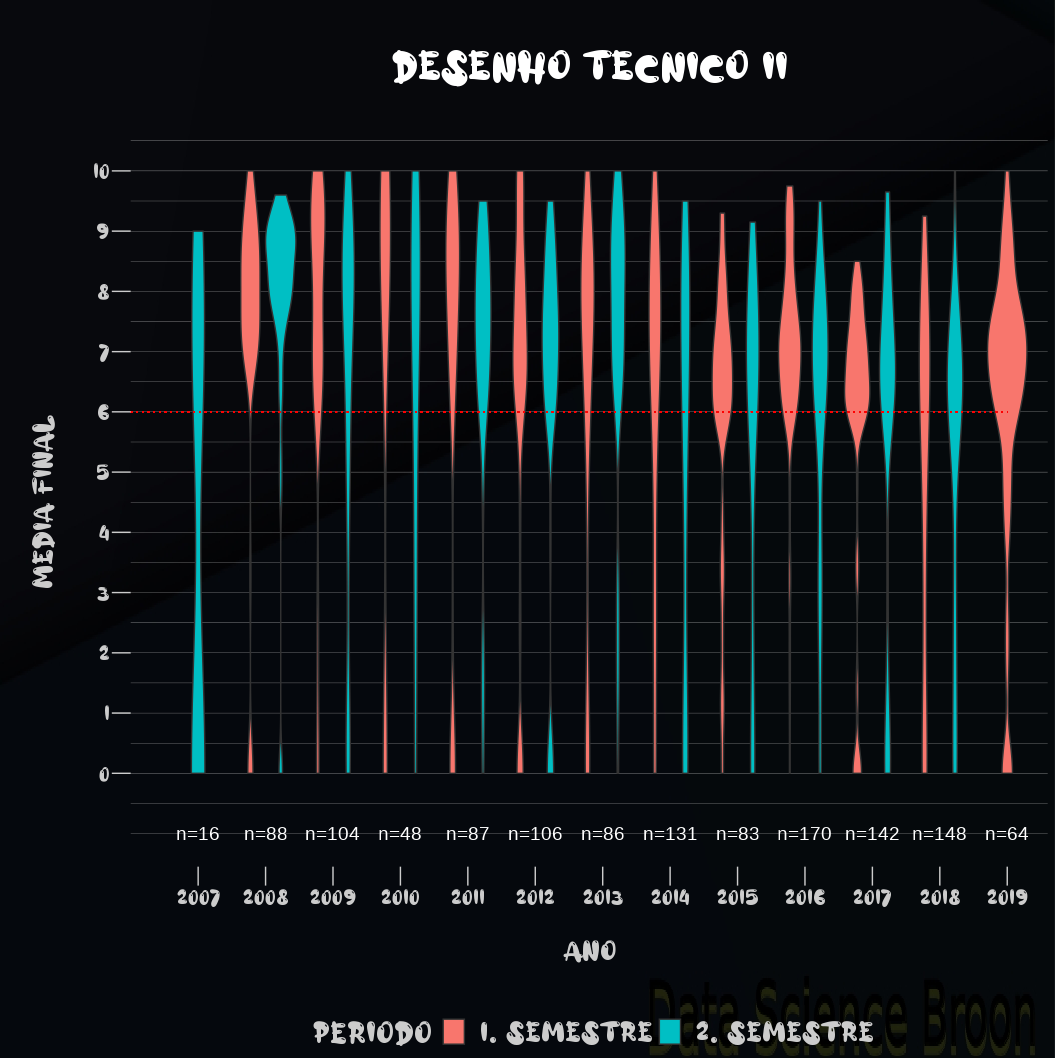
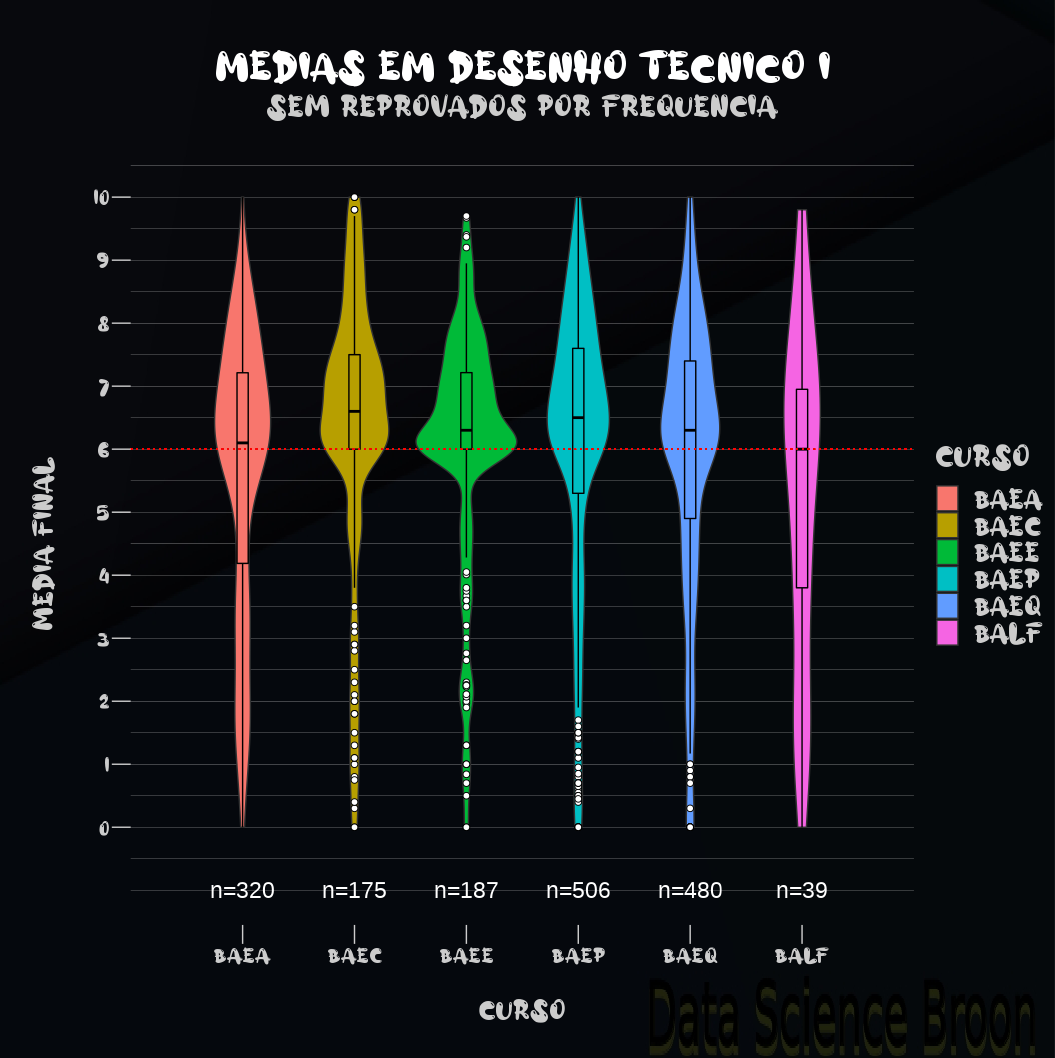
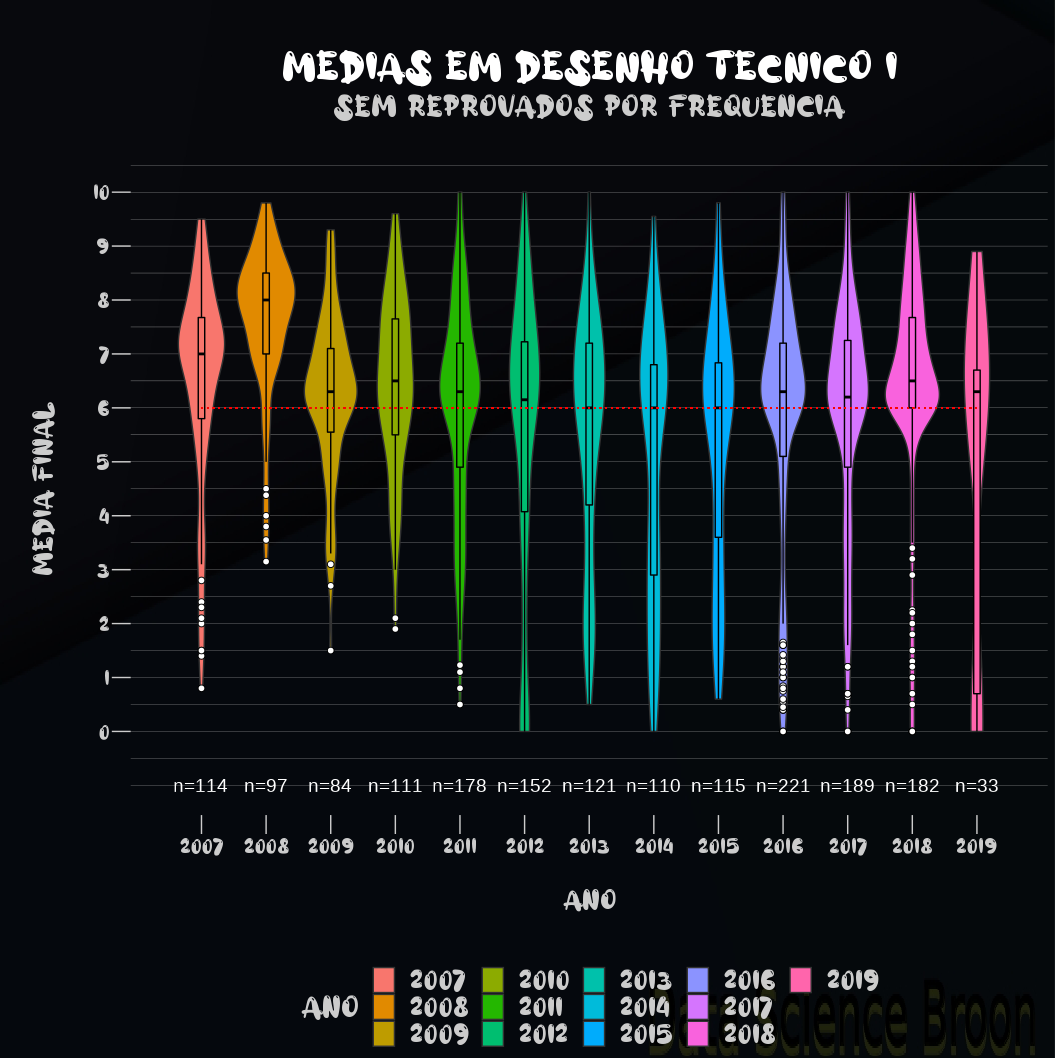
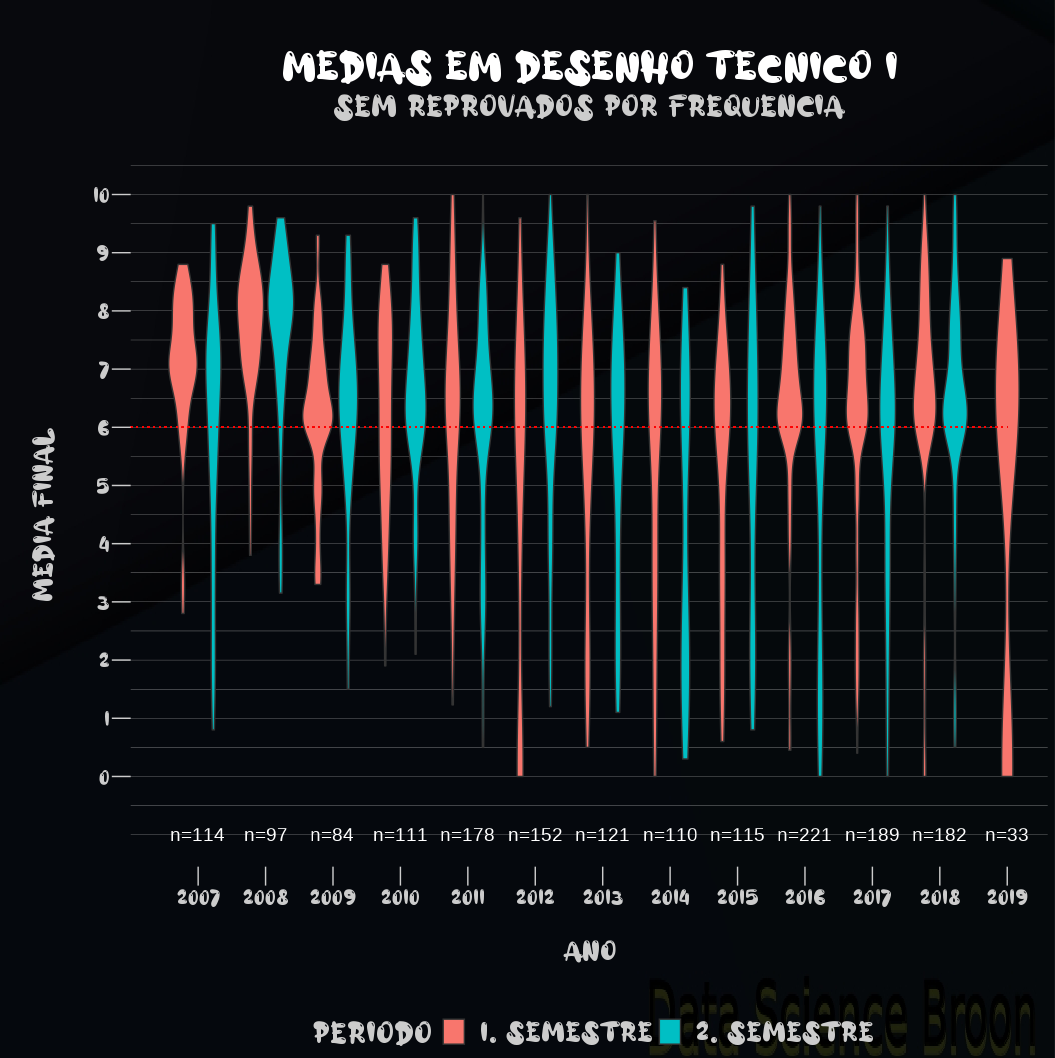
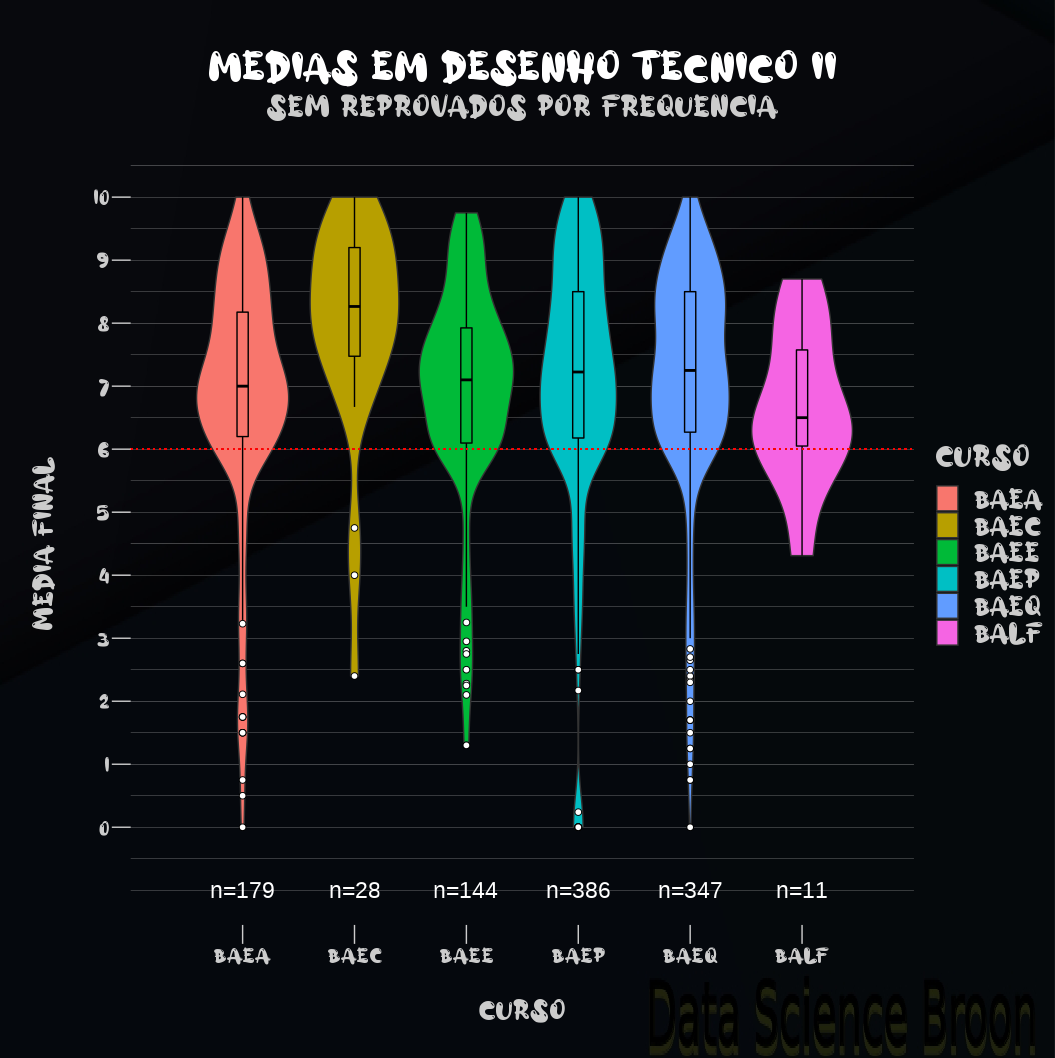
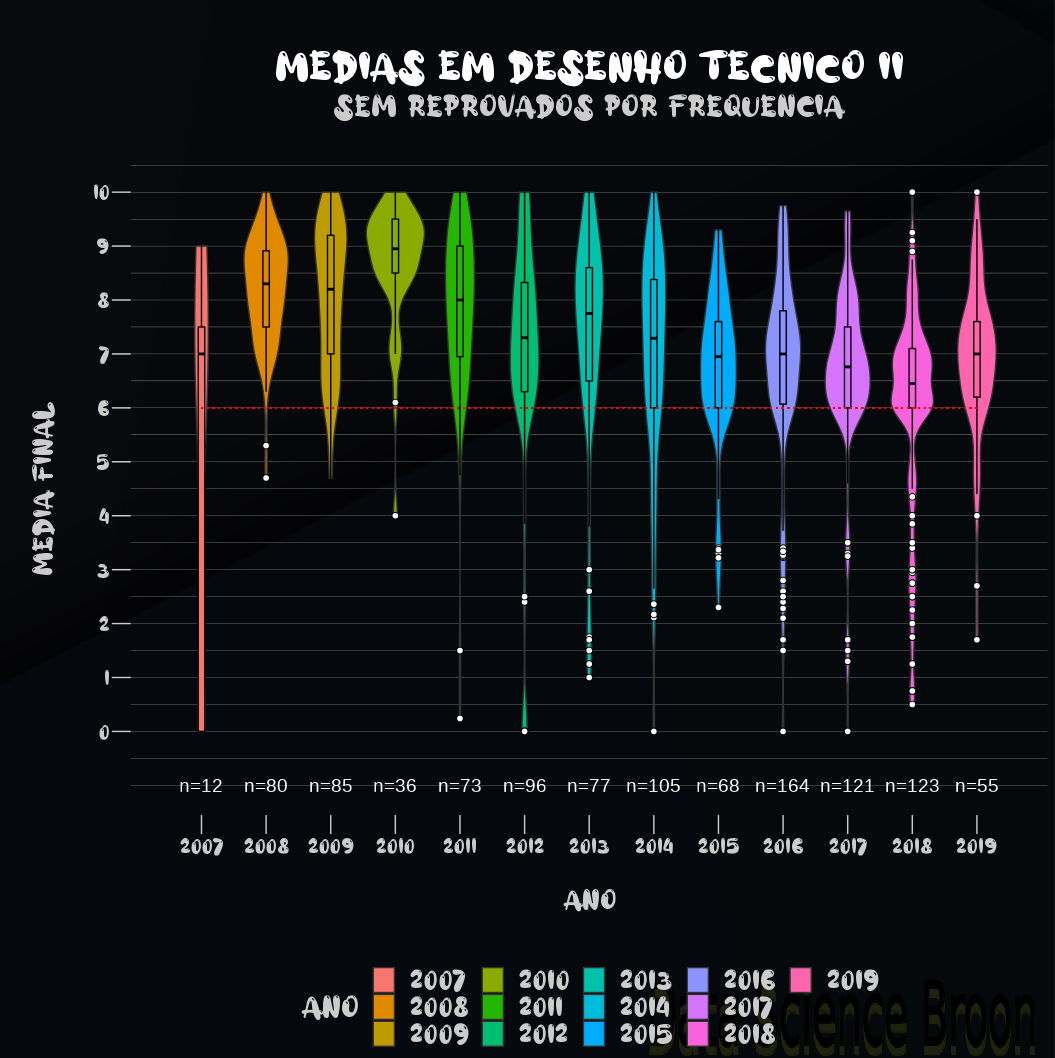
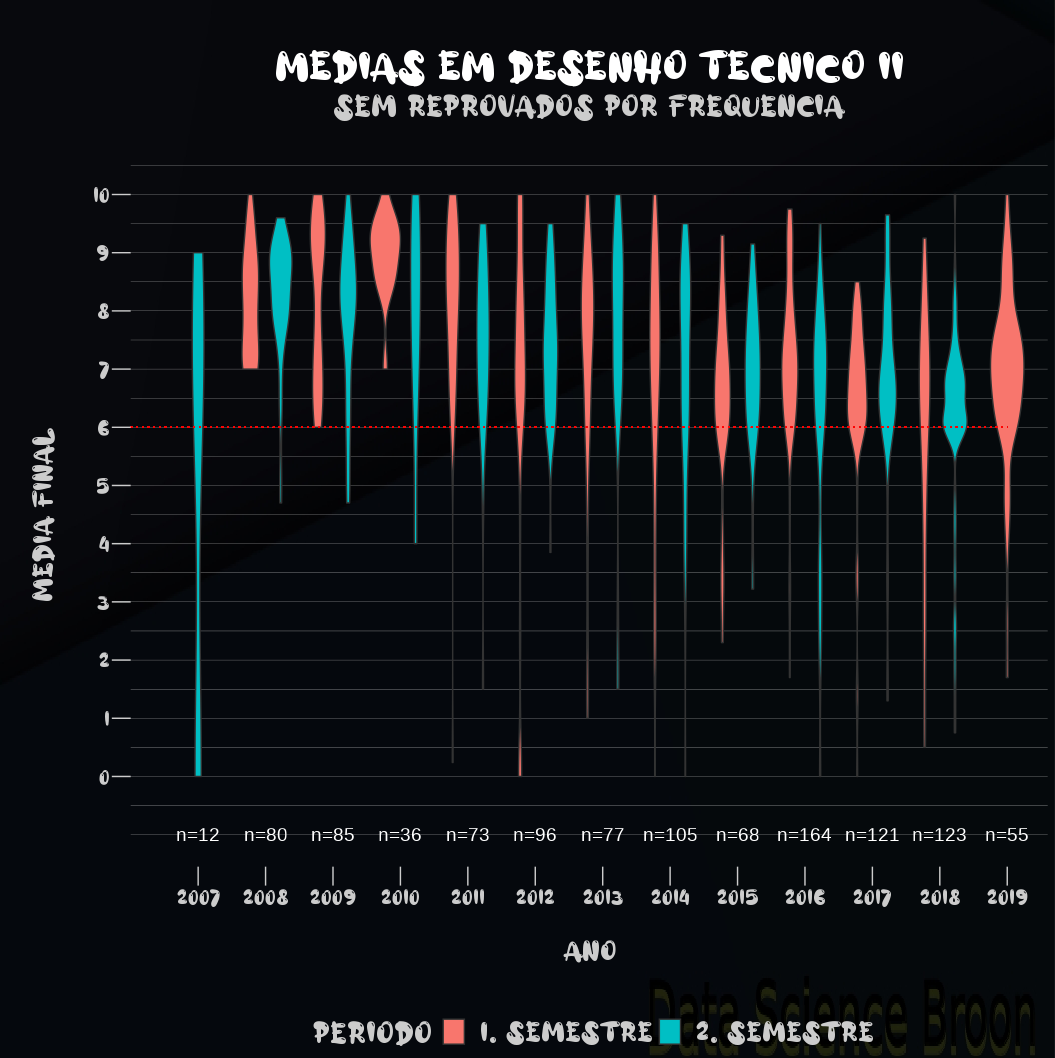
| |
Resumindo um pouco dos gráficos acima:
Os alunos de Desenho I em 2008 tiveram um desempenho superior nas notas em relação aos outros anos;
De 2009 até 2014 o desempenho caiu até começar a melhorar de 2015 até 2018;
Em Desenho II, o curso de BAEC aparece com desempenho superior nas notas, BALF é o curso com desempenho inferior, e os cursos restantes possuem estatísticas semelhantes. Obs: Desenho II é desenvolvida com o uso de softwares de CAD - (Desenho Auxiliado por Computador);
O desempenho dos alunos entre 2009 e 2013 foi superior em Desenho II com relação aos anos posteriores;
Sem reprovados por frequência, o desempenho por curso em Desenho I ficou mais homogêneo. O curso de BAEC apresenta notas melhores que BAEQ (provavelmente BAEQ possui mais alunos e poucos reprovados por frequência, o que pode justificar a mudança). O comportamento por ano se manteve, como no caso com todos os dados;
O comportamento das medianas no caso de Desenho II sem reprovados manteve o mesmo padrão, diferenças mínimas por curso, ano e período.
Agora vamos observar outros aspectos do nosso dataset…
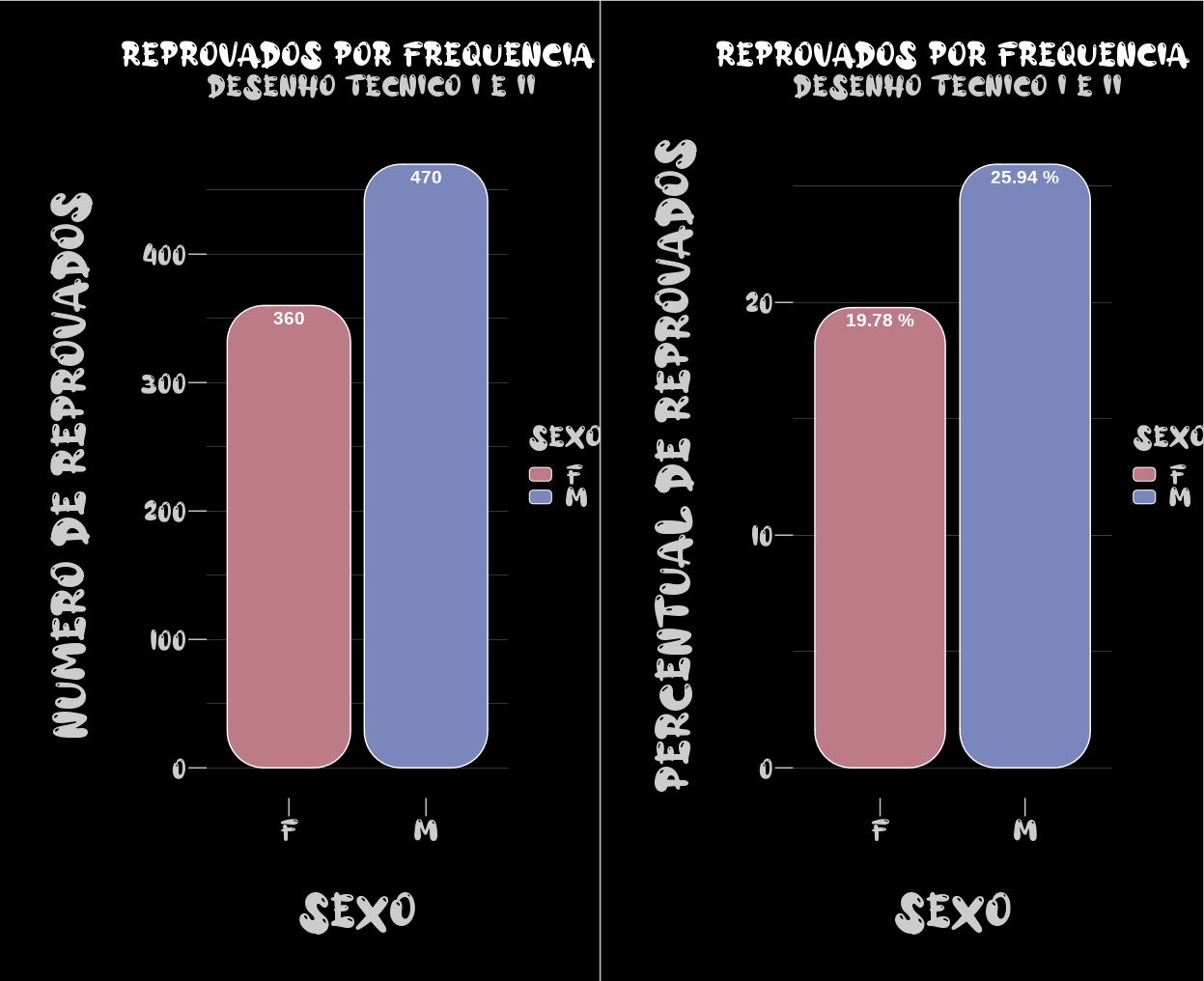
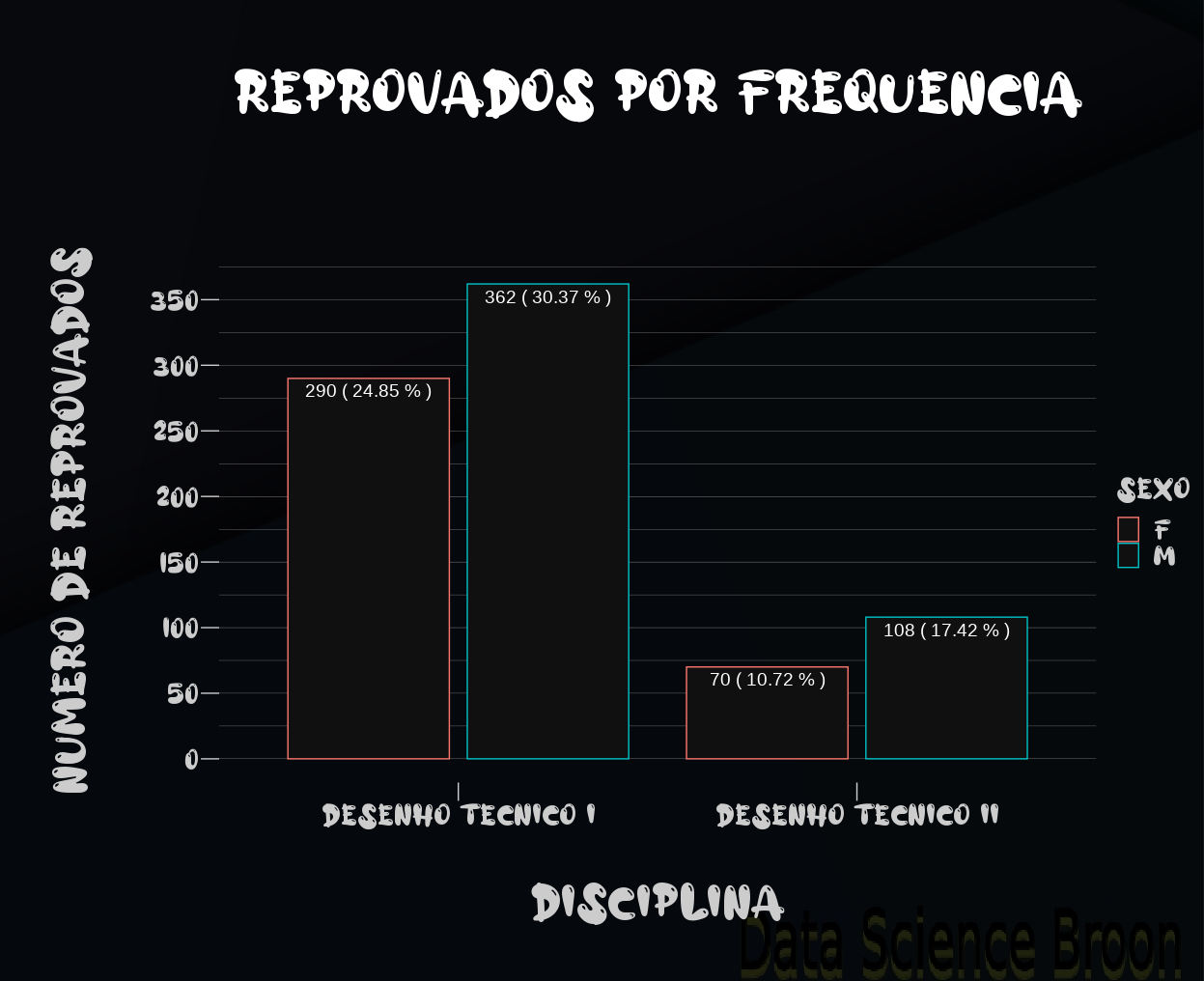
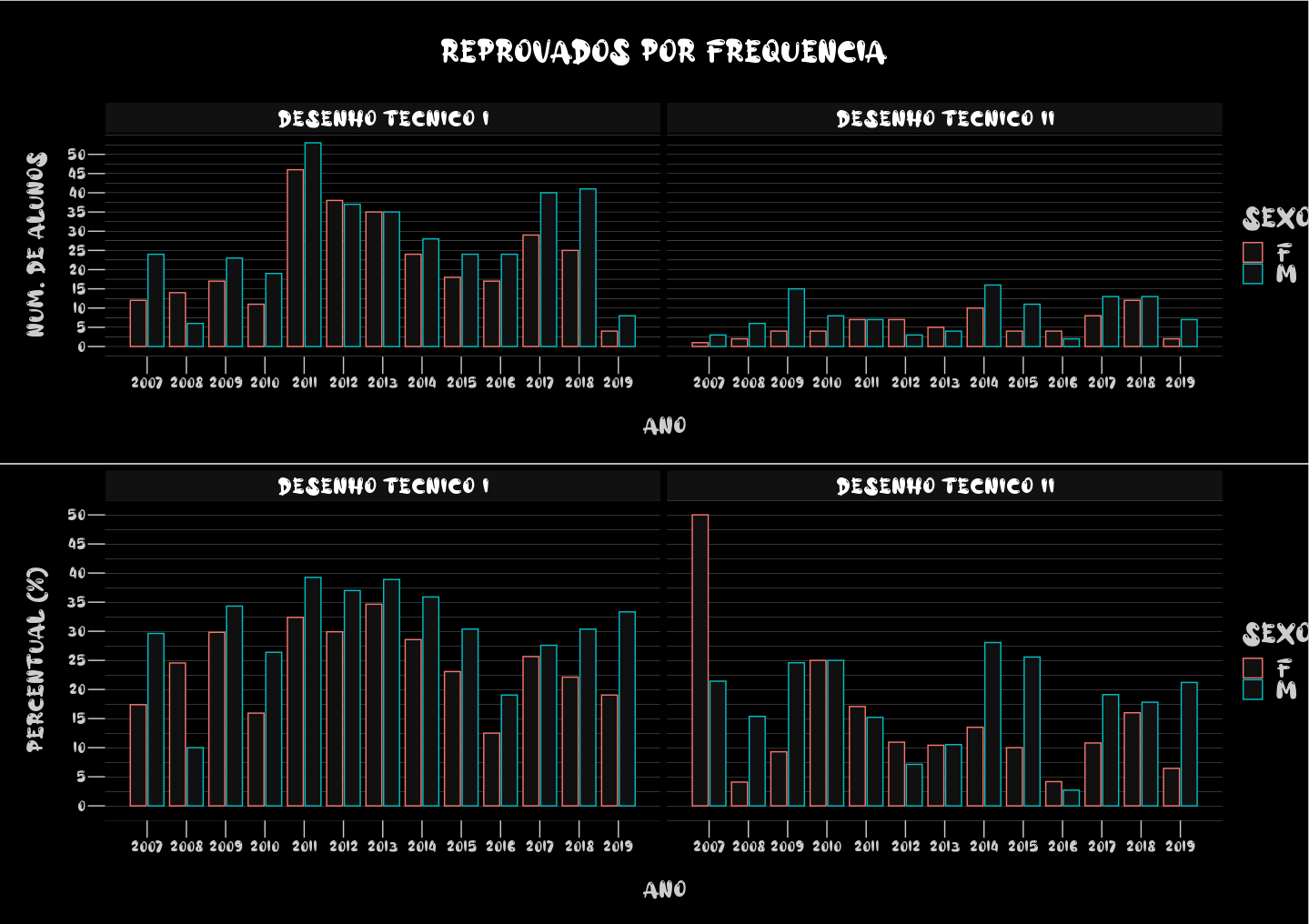
Interessante observação que as estudantes do sexo feminino reprovam menos em quantidade e percentual se comparadas aos estudantes do sexo masculino. O percentual apresentado nos gráficos é relativo ao universo de estudantes do sexo em questão, e não do total de alunos. Exemplo: se de uma turma de 100, 50 foram reprovados e 10 destes são estudantes do sexo feminino, então 20% dos estudantes do sexo feminimo reprovaram, e não 10%. O percentual é relacionado com o universo de reprovados, e não do total de alunos.
O mesmo acontece se observamos as reprovações por ano e por disciplina. Existem raríssimas exceções onde estudantes do sexo feminino reprovaram mais em quantidade/percentual do que do sexo masculino (2008 em Desenho I e 2014 em Desenho II).
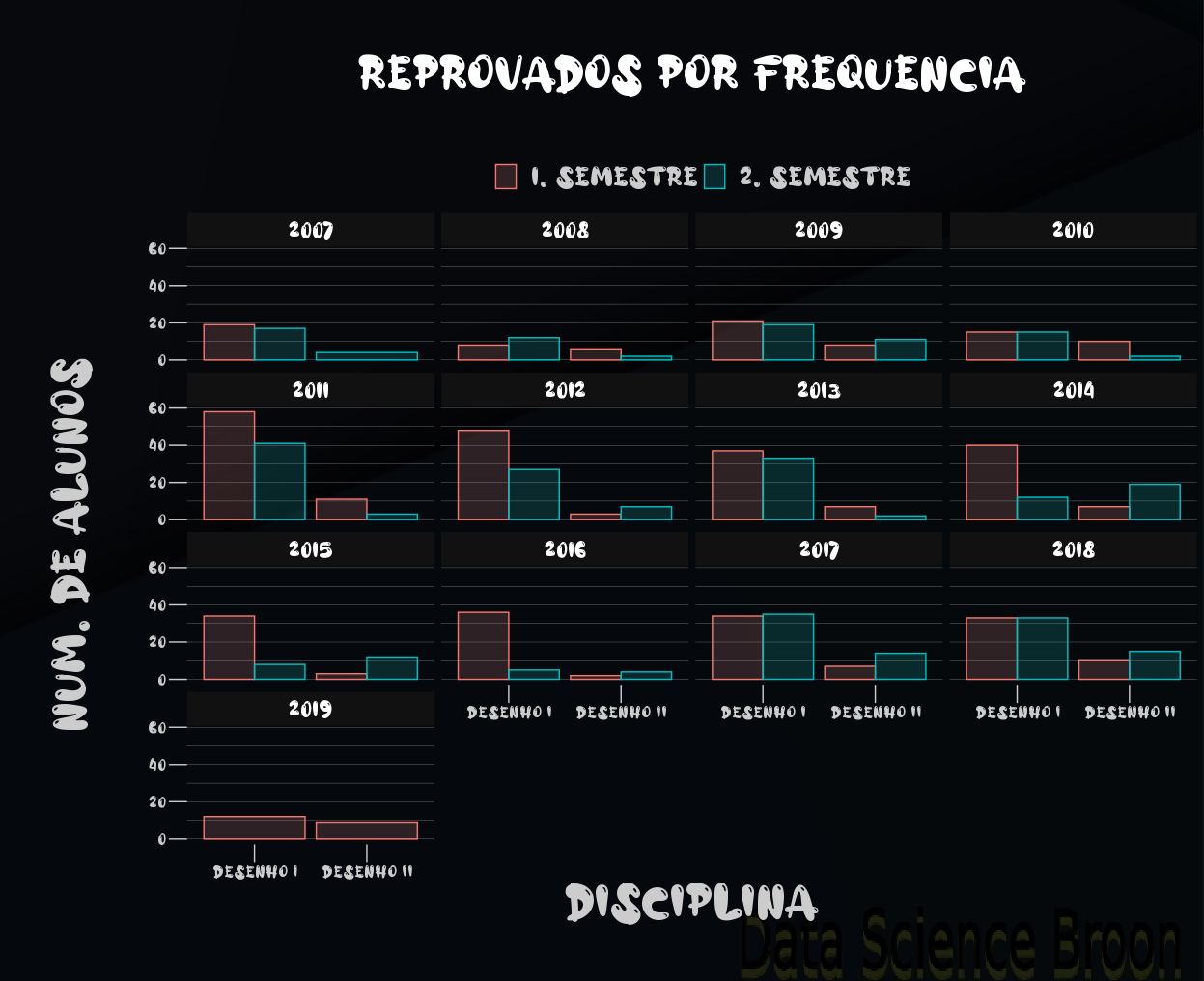

Outro caso interessante são as reprovações por disciplina, semestre e ano. Na maioria dos anos, as reprovações em percentual e absolutas são maiores no 1° semestre para Desenho I e no 2° semestre para Desenho II.
Faz sentido, já que Desenho I é pré-requisito para cursar Desenho II, que geralmente é no semestre subsequente.
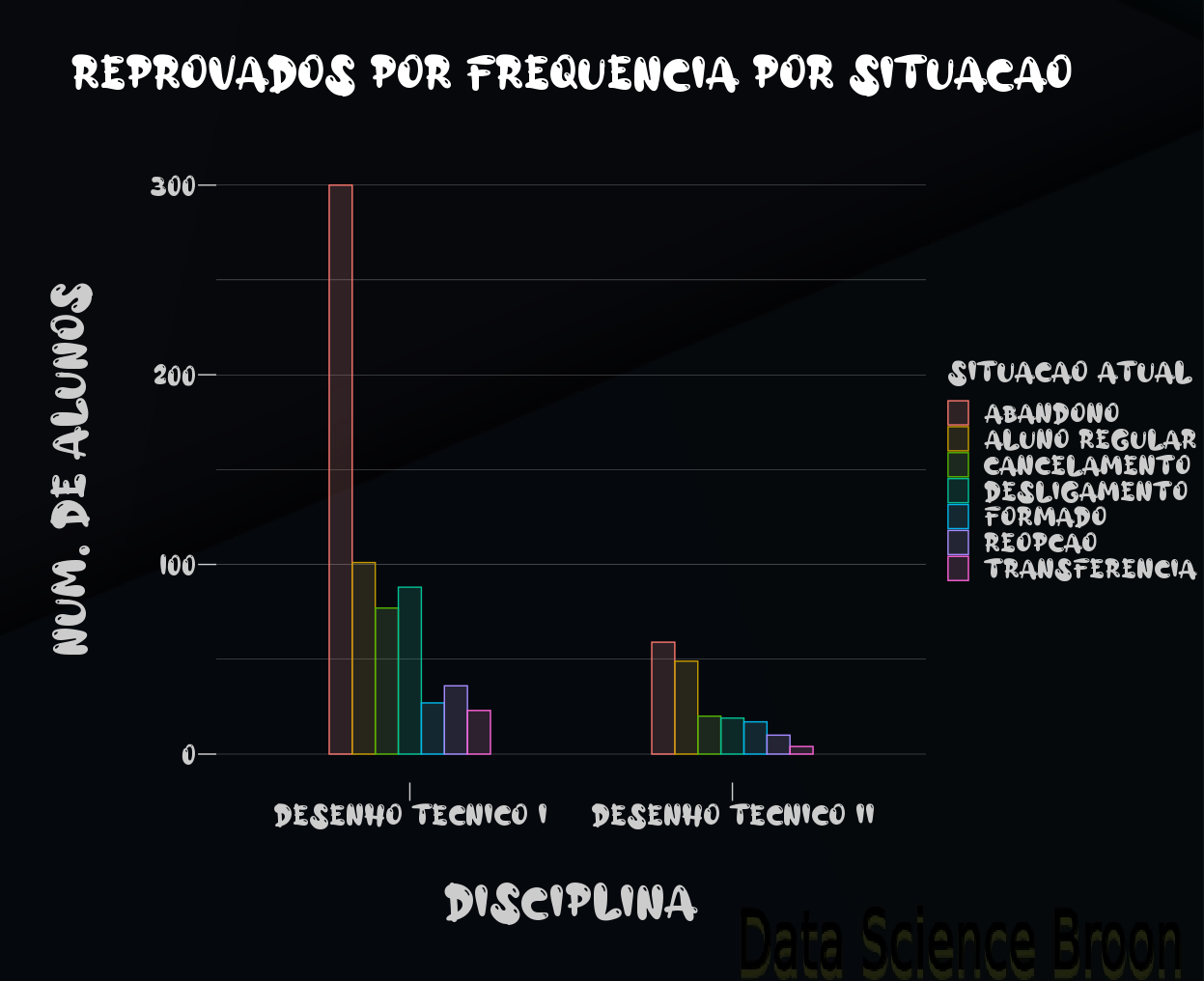
A maior parte dos reprovados por frequência em Desenho I acaba abandonando o curso de origem. Esta é uma realidade preocupante evidenciada pelo gráfico acima. O cenário é menos intenso em Desenho II, porém ainda preocupante. Vejam que uma parcela muito pequena dos estudantes que reprovaram nos Desenhos I e II se formaram ou são alunos regulares.
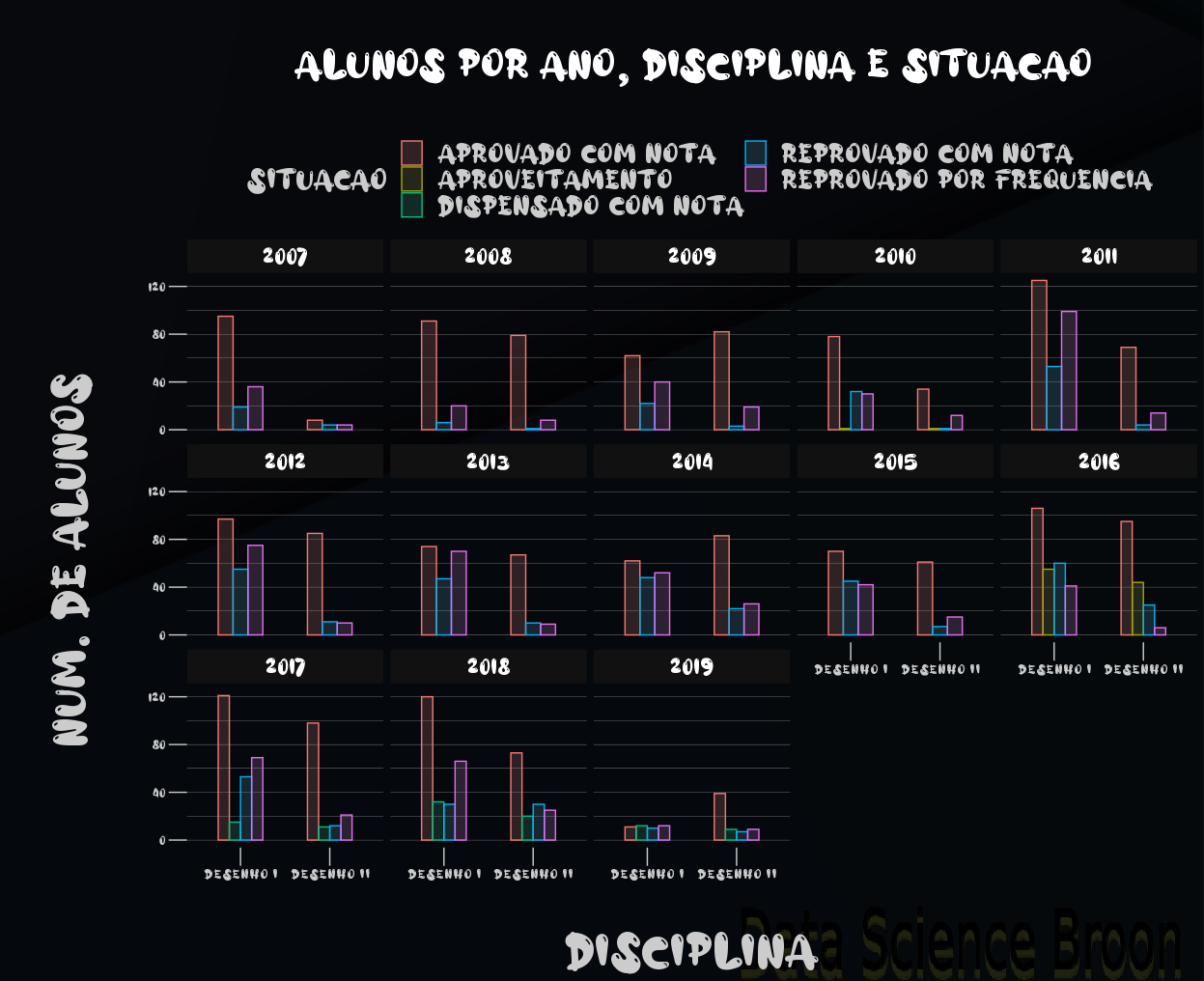
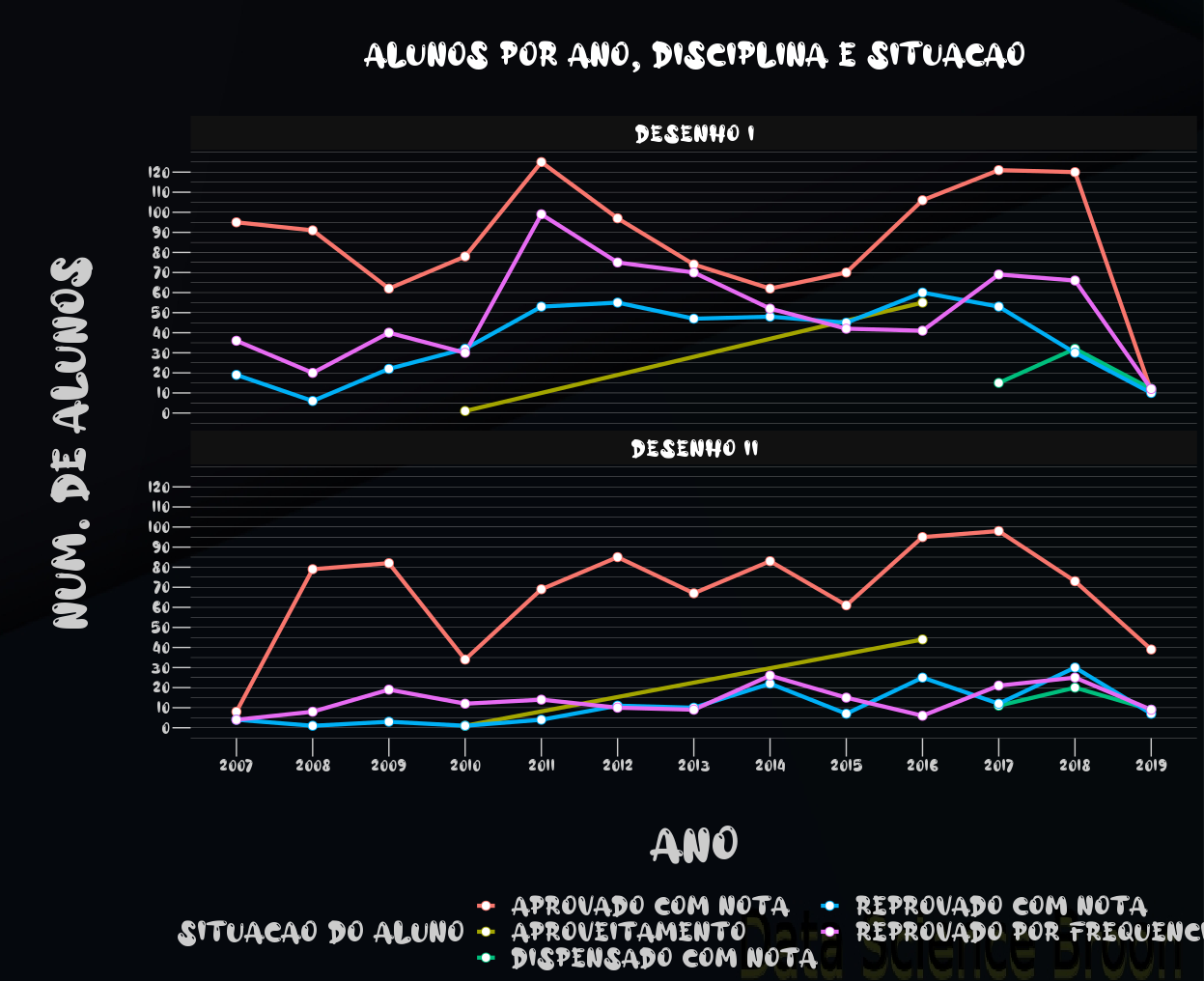
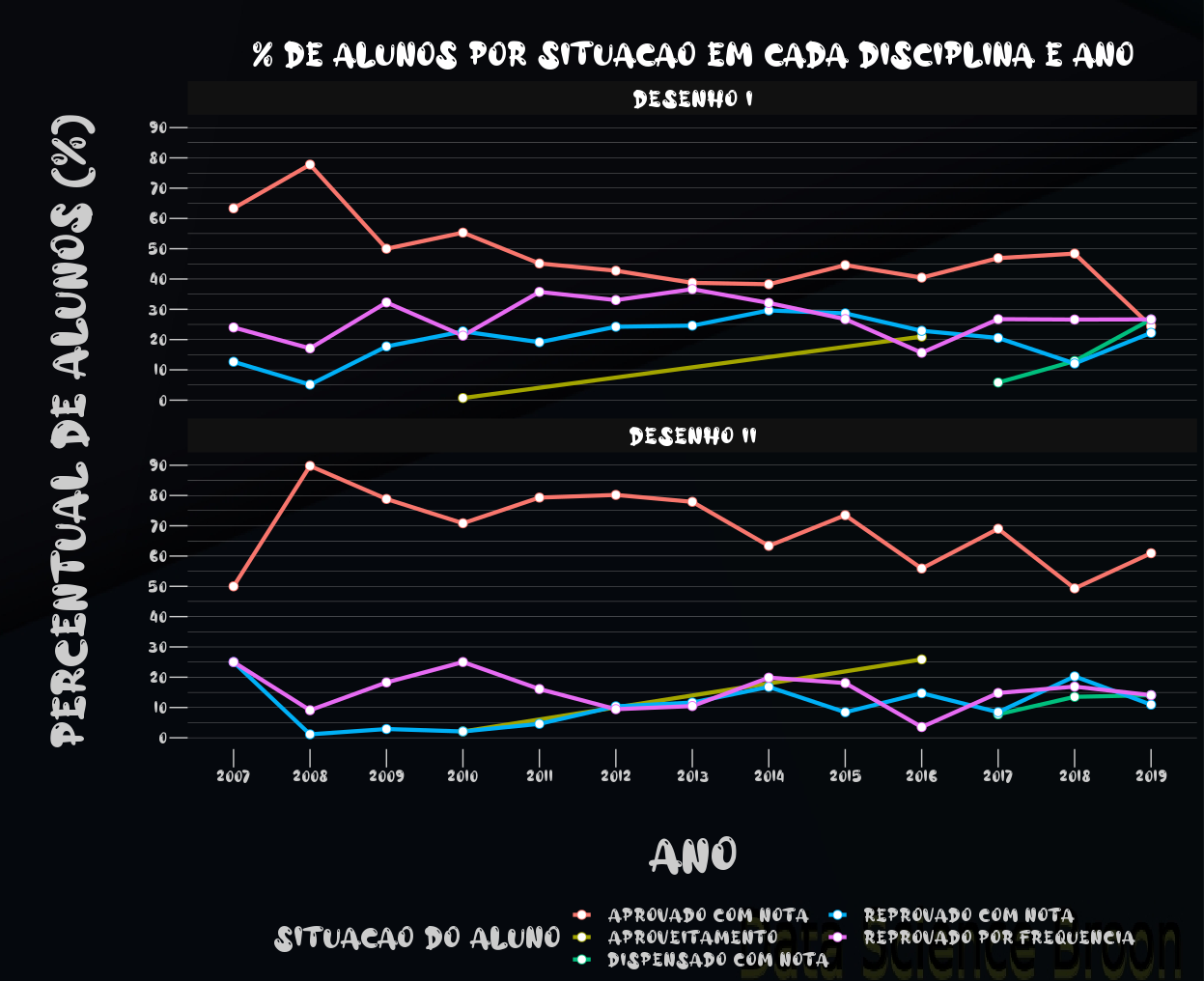
A diferença das reprovações por frequência e aprovações entre os Desenhos é evidenciada acima. Estudantes de Desenho I e II aparentemente tem mantido constante o seu desempenho nos últimos anos, de uma forma geral, apesar do cenário não ser satisfatório. Houveram variações significativas na quantidade de estudantes neste período analisado.
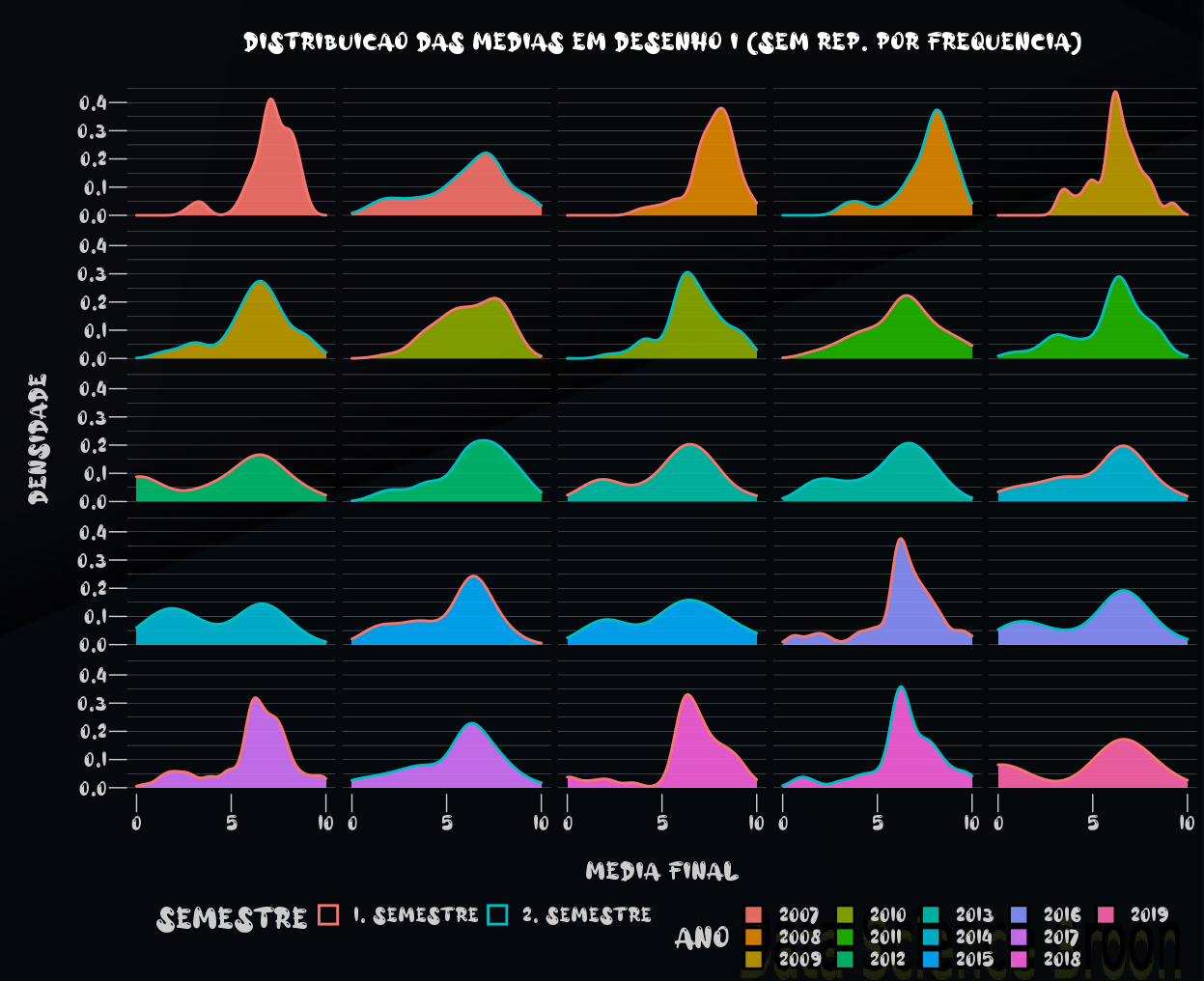
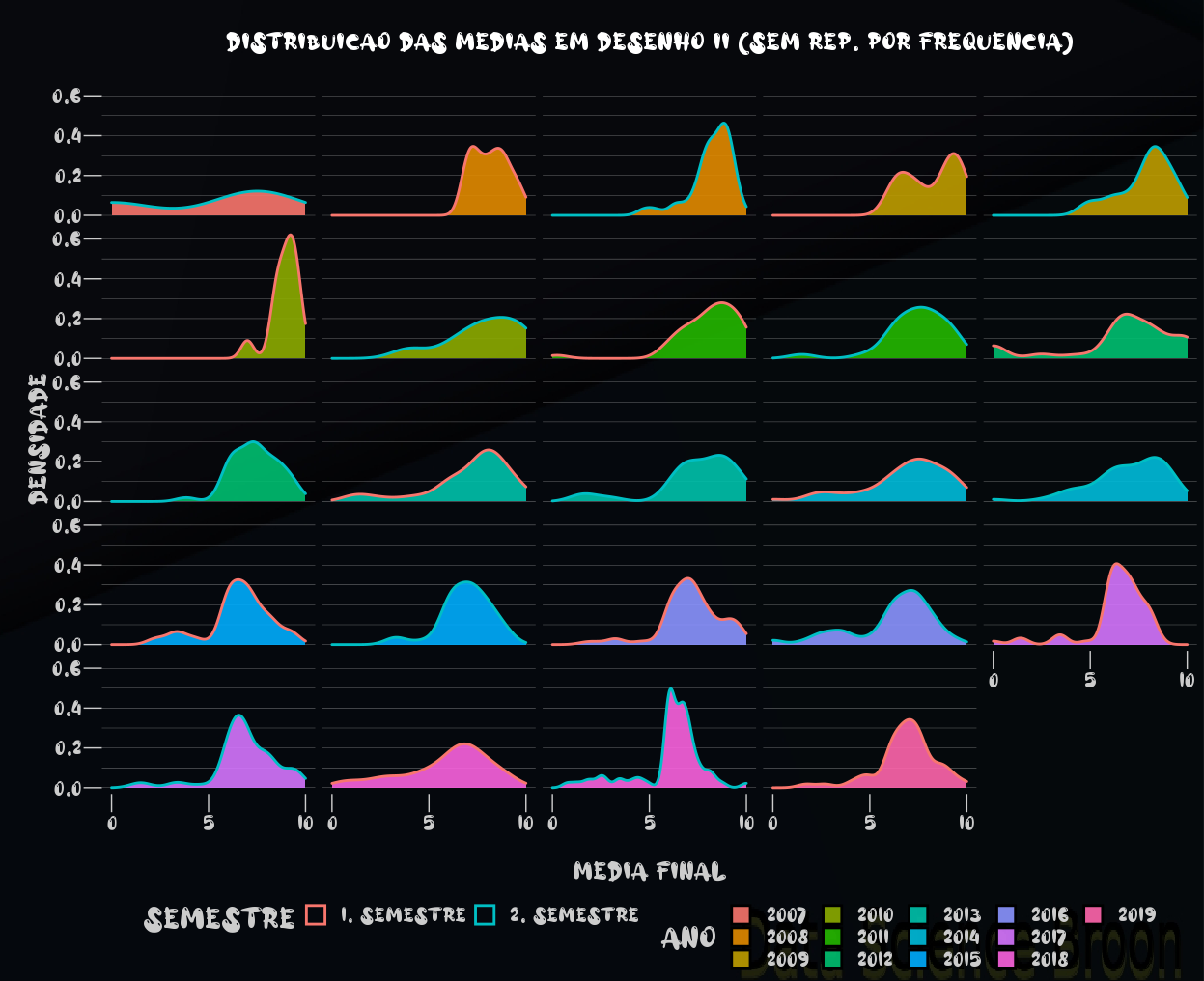
A distribuição das médias por ano e semestre, tanto em Desenho I como II, se concentram na nota 6, que é a nota mínima para aprovação. Em Desenho II, o desempenho dos estudantes tem sido muito superior ao de Desenho I.
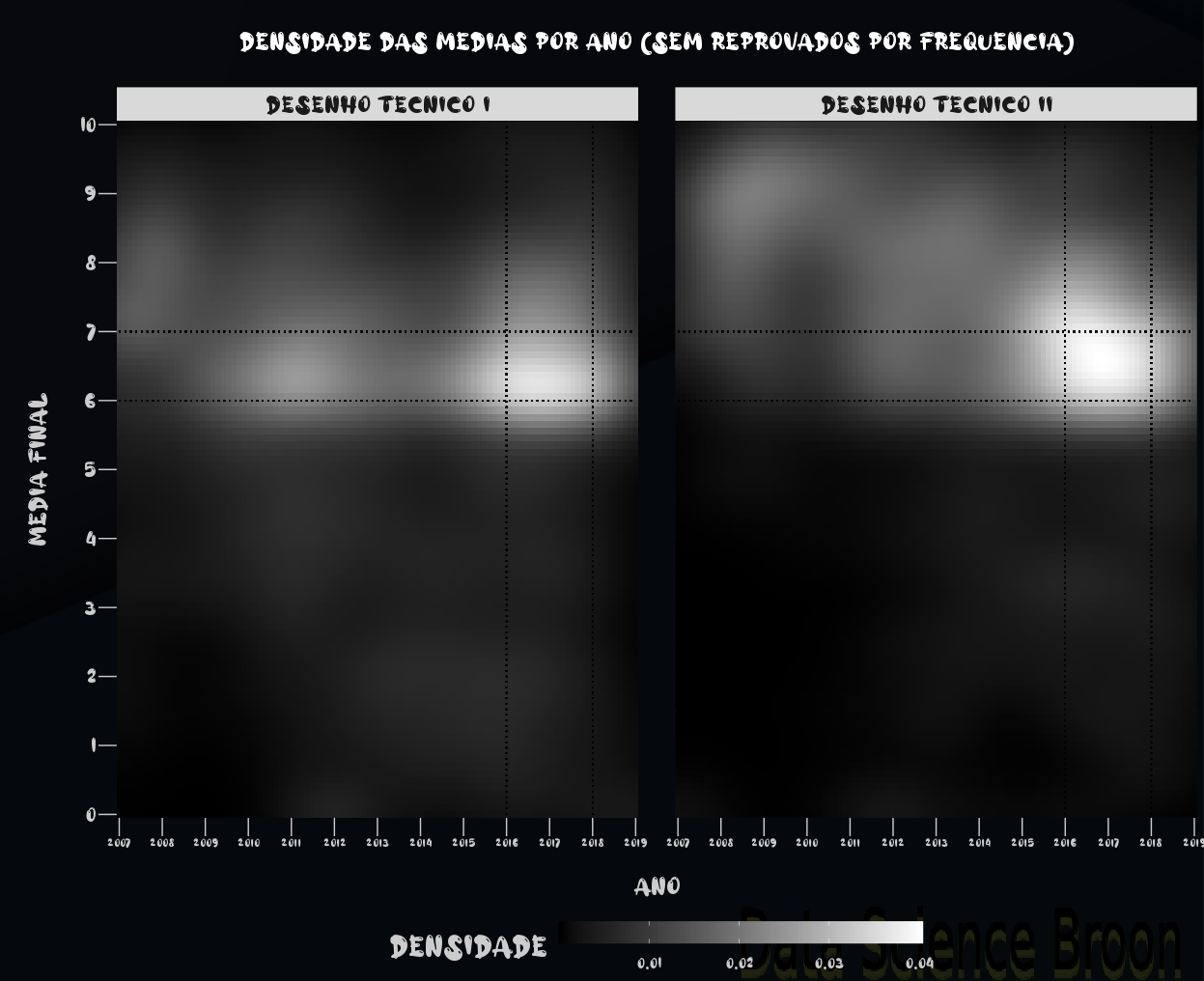
Aqui novamente observamos a maior concentração das médias entre as notas 6 e 7, em Desenho I e II. O cenário é mais positivo em Desenho II, apesar de aparentemente ter piorado nos últimos anos (pois ocorreu maior concentração das médias em torno do 6 e 7, e menor concentração em notas mais altas, como aconteceu em anos entre 2007 e 2014).
| |
Apesar dos resultados das análises serem visíveis, temos que corroborar com o uso de métodos estatísticos.
Parte III - Estatísticas do Dataset
Vamos testar hipóteses sobre as variáveis independentes e a nota final dos alunos. Primeiro, separamos as análises, uma incluindo dados de Desenho Técnico I e a outra com dados de Desenho Técnico II, já que são disciplinas distintas. Começaremos com Desenho I.
Primeiro, transformamos os dados da coluna do período para números, representando o primeiro e o segundo semestres. Na sequência, o período e o ano são transformados em fatores, para trabalharmos na sequência com este formato.
| |
Caso I: Performance dos Estudantes por Semestre e Ano em Desenho Técnico I
Primeiro vamos checar as três pressuposições da análise de variância:
(1) Amostras independentes – uma observação não pode ser influenciada pela anterior ou pela próxima. Esse pressuposto garante que os dados sejam coletados aleatoriamente dentro do espaço amostral.
(2) Resíduos seguem uma distribuição normal – assume-se que a média geral dos resíduos é igual a zero, ou seja, distribuem-se normalmente.
(3) Homogeneidade das variâncias entre os grupos – as variâncias dentro de cada grupo é aproximadamente igual àquela dentro de todos os grupos. Desta forma, cada tratamento contribui de forma igual para a soma dos quadrados.
No caso de (1): podemos assumir que cada estudante é responsável por seu respectivo esforço e, por consequência, suas notas. A influência entre alunos é desprezível neste caso. Portanto, o primeiro pressuposto está ok (isso vale para todas as análises na sequência).
No caso de (2): realizar o teste de shapiro-walk, para checar se os resíduos/erros possuem uma distribuição normal. Para isso, vamos antes executar uma análise de variância com o aov no R
| |
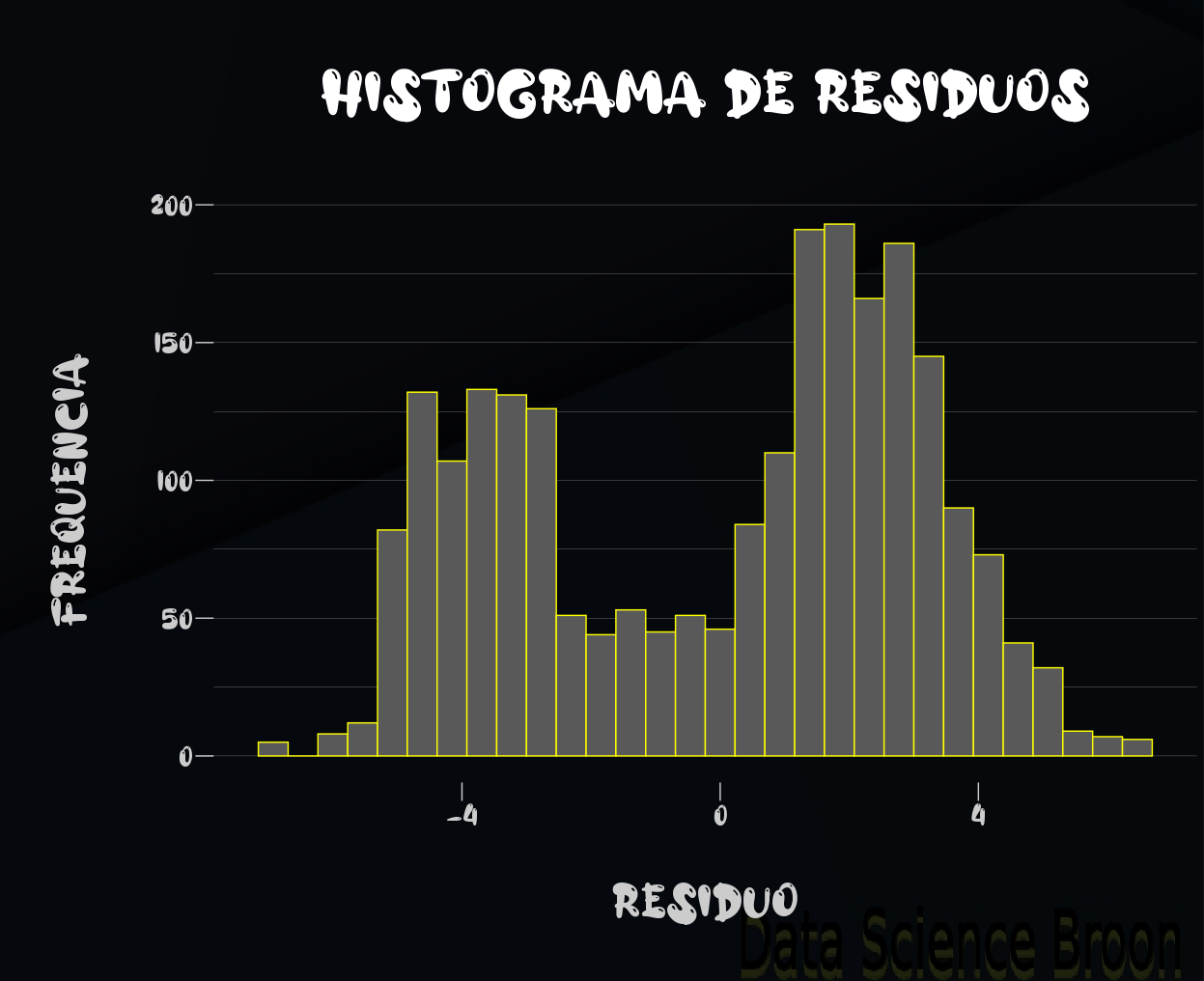
p-value < 0.05 : H0 (Hipótese Nula) rejeitada, a evidência de que a distribuição de resíduos não segue uma distribuição normal é estatisticamente significante.
Resultado: os resíduos não têm uma distribuição normal.
No caso de (3): teste de homogeneidade da variância entre grupos. Primeiro manualmente e depois com o teste de Levene.
| |
Resultado: 1.62. A variação entre os grupos possui discrepâncias. Vamos confirmar com testes de Levene.
| |
p-value < 0,05: H0 rejeitado em todos os testes de Levene, a evidência de que as variações entre os grupos (anos, semestres e ambos) são diferentes é estatisticamente significante.
Oh good ! E agora?
Calma, podemos recorrer aos testes não-paramétricos…
Uma das técnicas que é possível utilizar com violações das pressuposições da anova é o teste de Kruskal-Wallis. É testado se a função de distribuição das médias entre os grupos é igual (H0).
| |
p-value < 0,05: H0 rejeitado em todos os testes de Kruskal-Wallis. Portanto, a diferença de distribuição das médias em pelo menos um dos grupos de anos e semestres é estatisticamente significante.
Vamos observar graficamente estes dados.
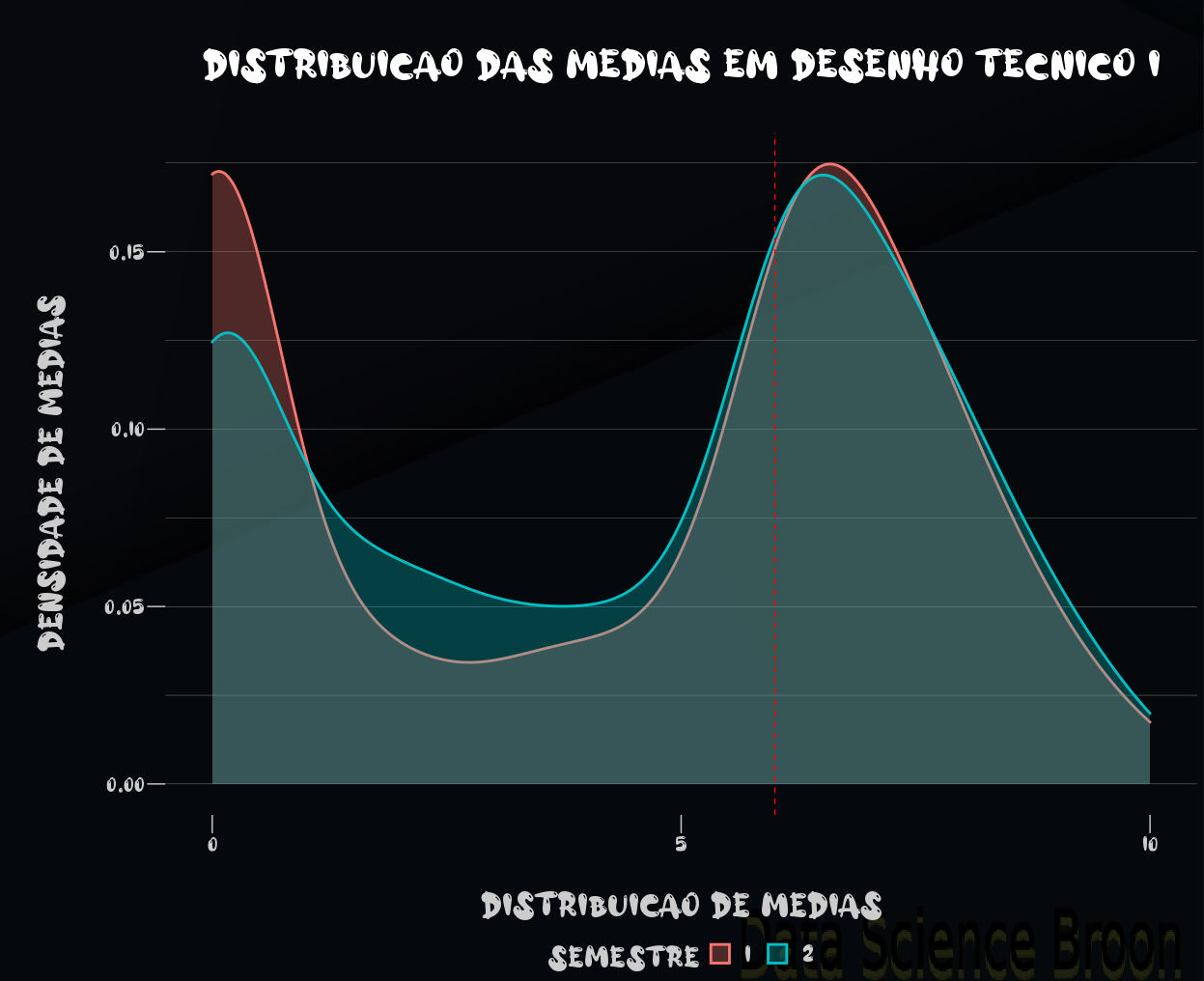
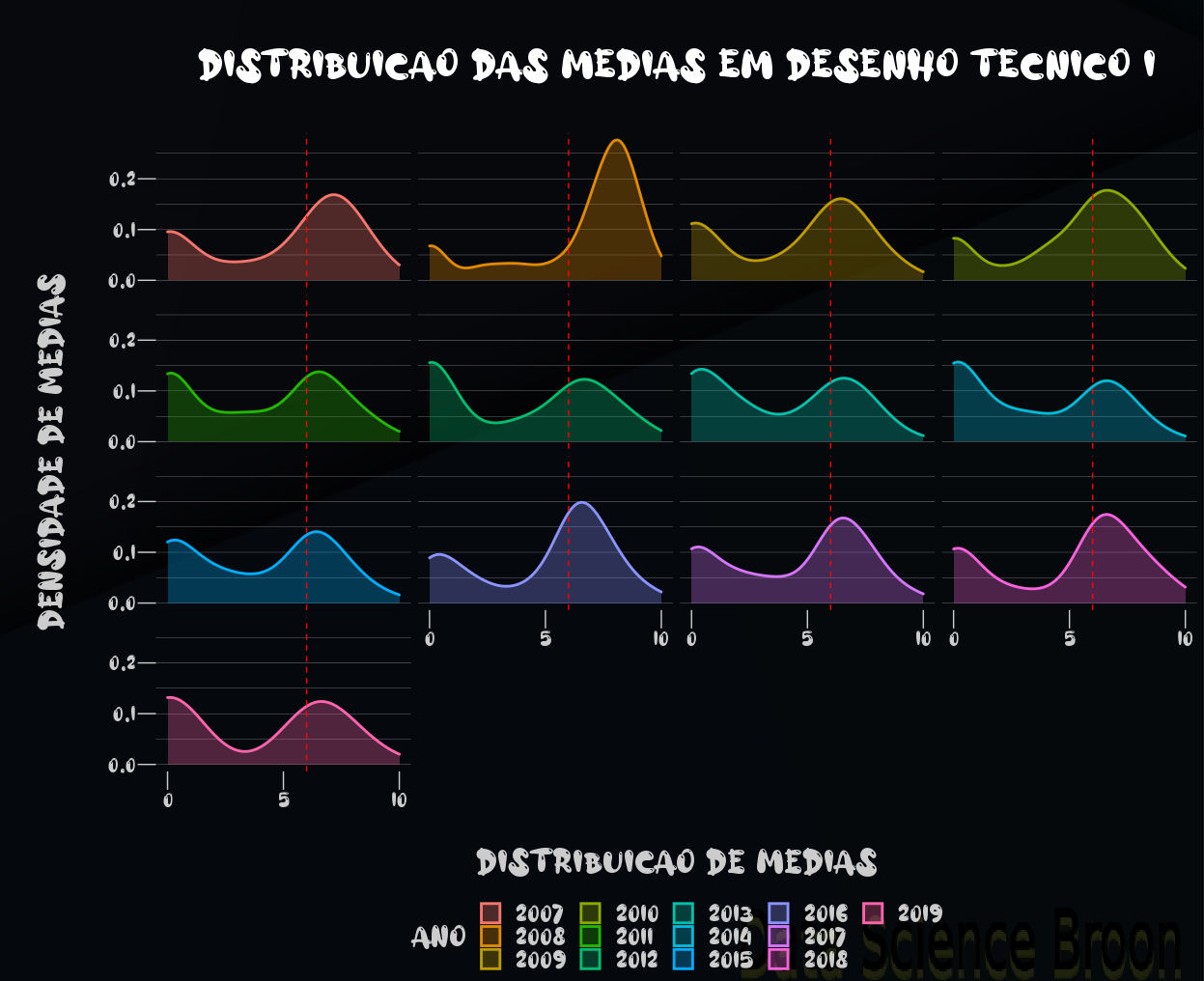
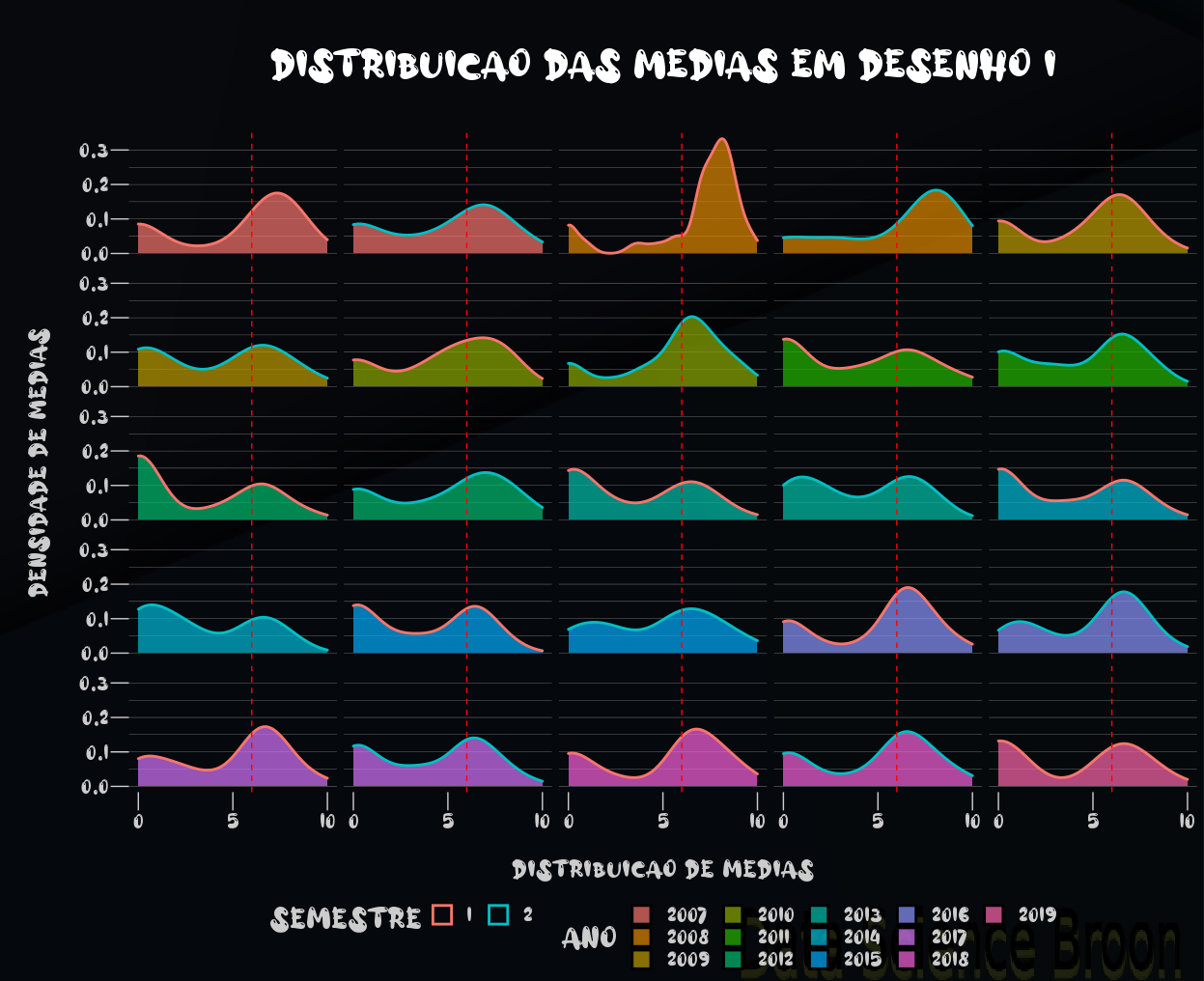
É possível observar que no caso dos semestres, as distribuições possuem alguma semelhança. Por isso o p-value dos semestres como tratamento resultou em um valor mais próximo de 0.05. Ao verificarmos ano e ambos ano e semestre, as diferenças entre os grupos se mostraram mais significativas.
Agora a questão que fica é: quais grupos possuem diferença significativa?
Antes vamos aplicar o teste de size effect com a função multiVDA. O teste indica a probabilidade da amostra de um grupo ser maior que a de outro grupo.
| |
Agora para finalizar vamos aplicar o teste de dunncan (dunnTest) para checar quais grupos de atributos pertencem a mesma classe de médias. Em outras palavras, quais grupos não possuem diferença estatística significante comparado com outros.
| |
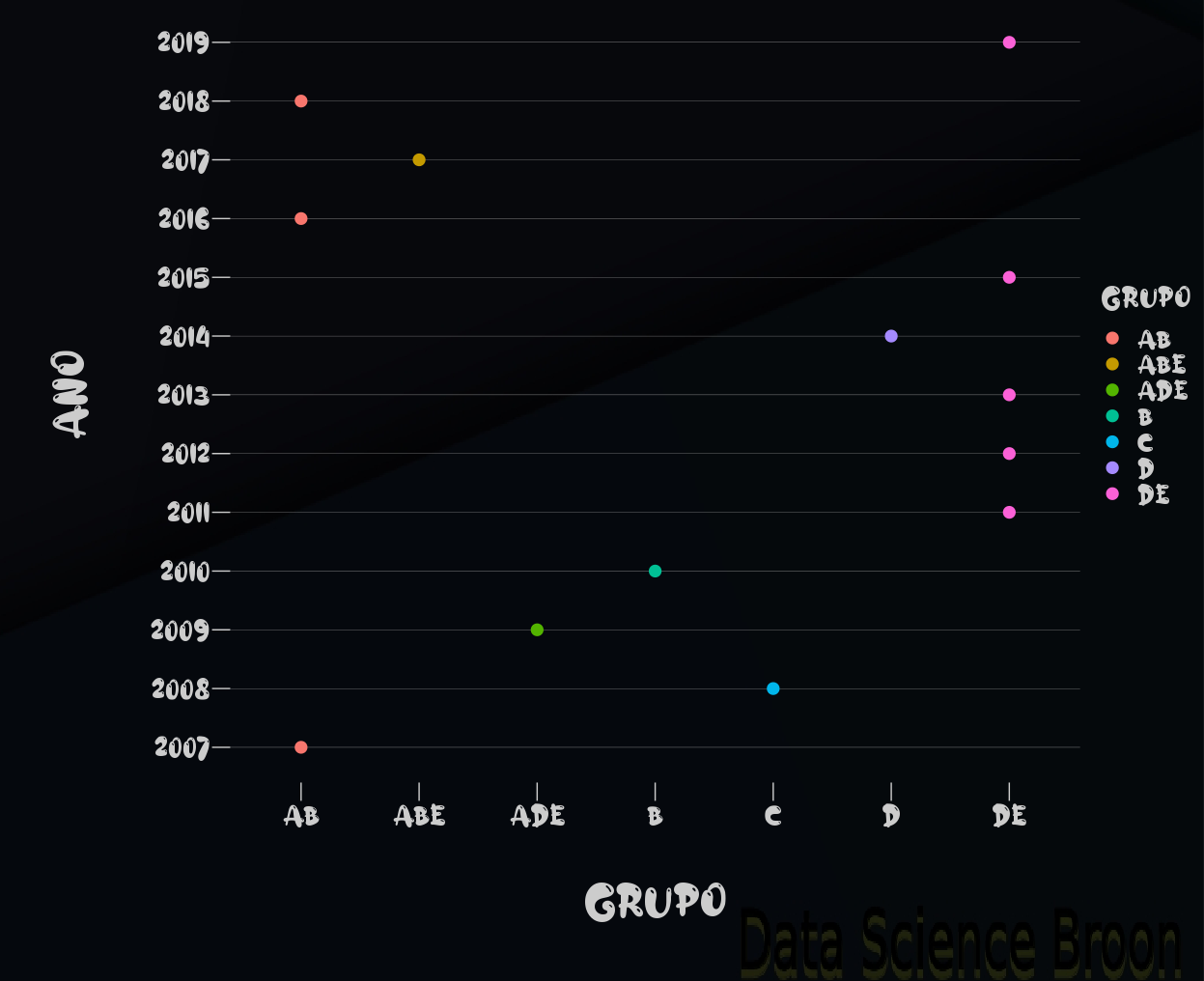
As médias dos alunos em anos que pertencem a mesma label não possuem diferença estatística significativa. Este é o resultado que o teste nos trouxe.
Infelizmente não é possível utilizar mais de uma variável dependente neste teste, mas a solução do problema é uma simples manipulação do dataframe, conforme apresento abaixo.
| |
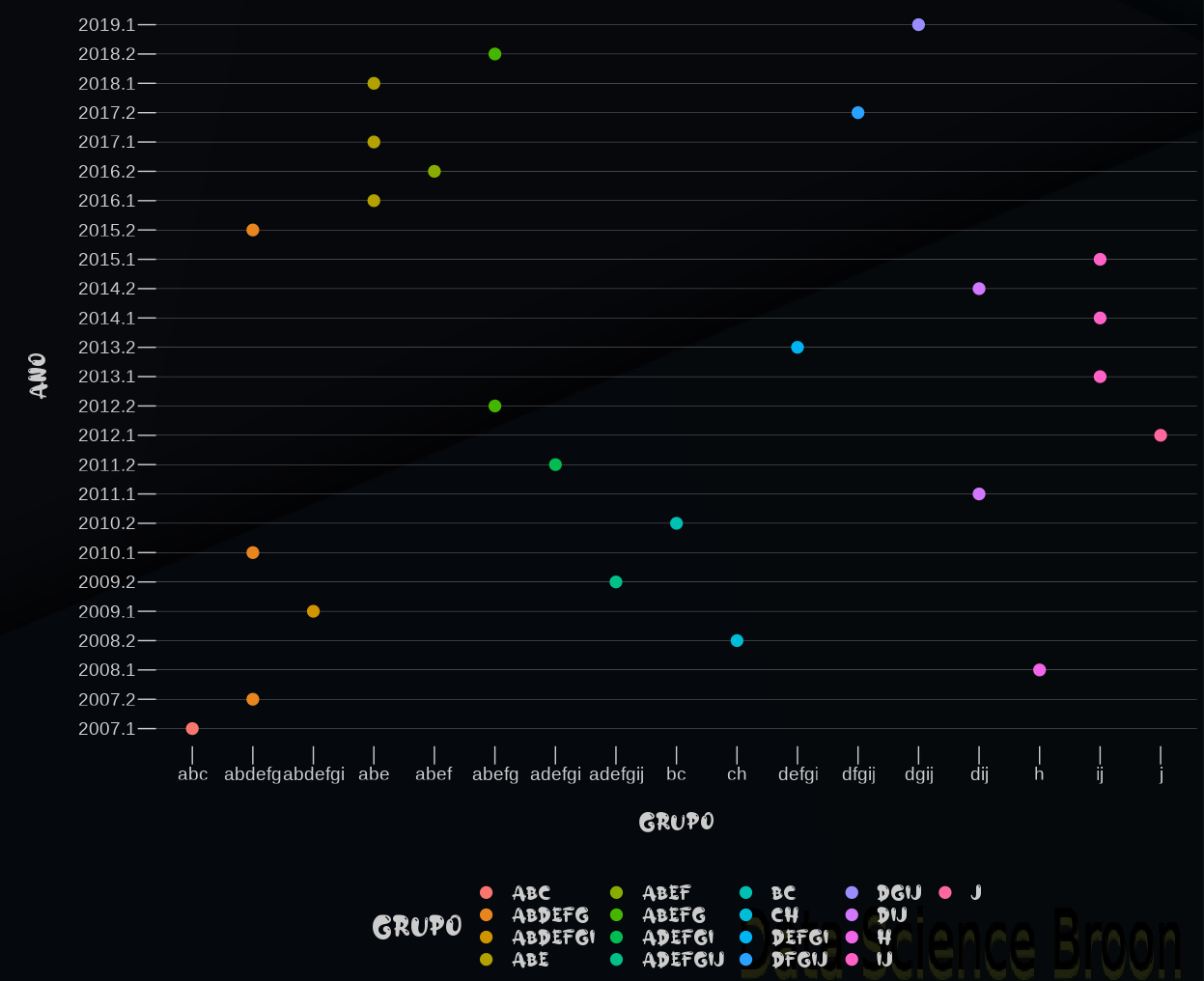
Agora vamos proceder as mesmas análises, porém com os alunos de Desenho Técnico II.
Caso (1): podemos assumir que cada estudante é responsável por seu respectivo esforço e, por consequência, suas notas. A influência entre alunos é desprezível neste caso. Portanto, o primeiro pressuposto está ok.
Caso (2): Os resíduos seguem uma distribuição normal?
| |
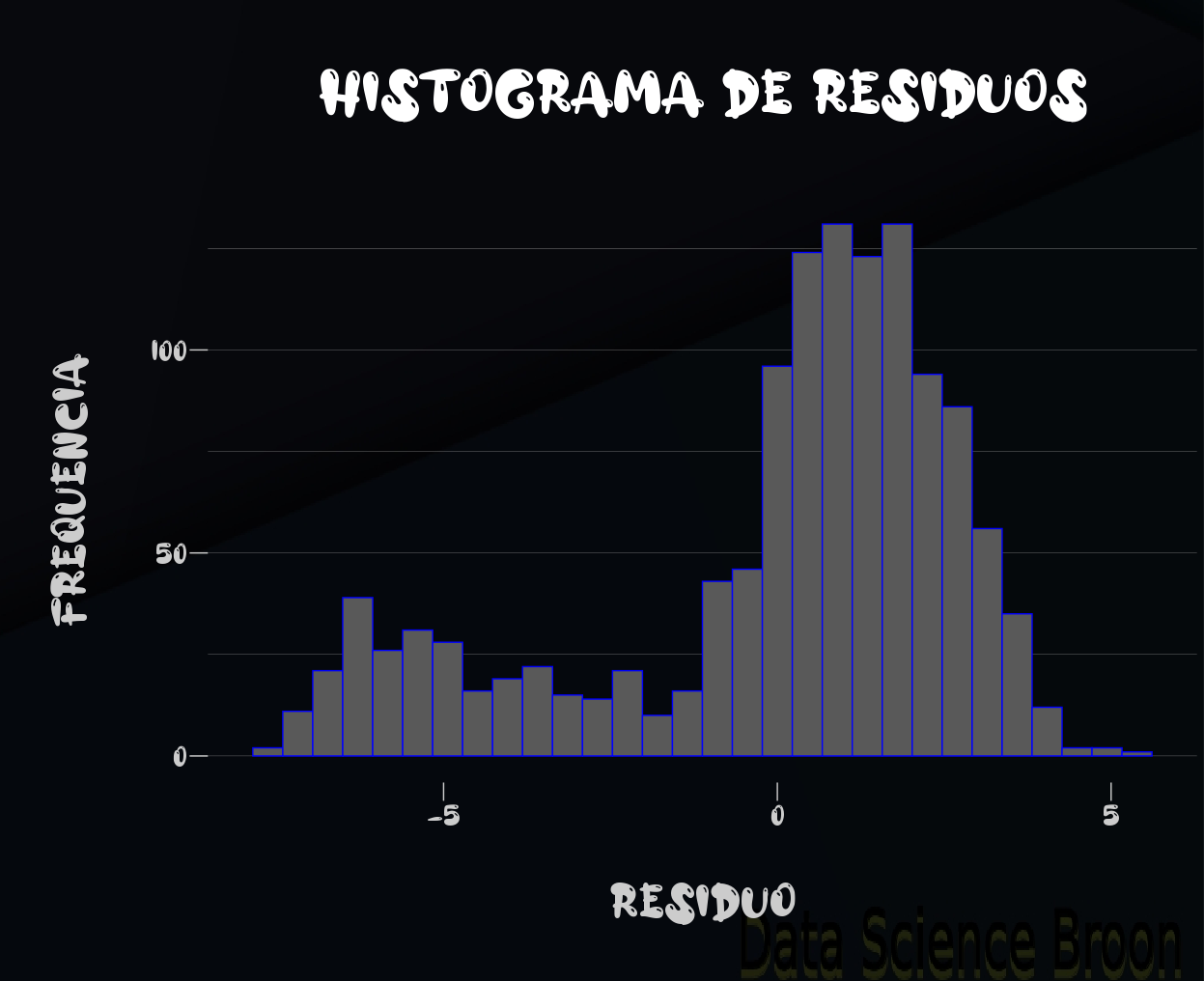
p-value < 0.05 : H0 (Hipótese Nula) rejeitada, a evidência de que a distribuição de resíduos não segue uma distribuição normal é estatisticamente significante.
Resultado: os resíduos não têm uma distribuição normal.
Caso (3): teste de homogeneidade da variância entre grupos.
| |
Onde p-value < 0,05: H0 rejeitado, a evidência de que as variações das médias entre os grupos (anos, e ambos semestres e anos) são diferentes é estatisticamente significante.
Onde p-value >= 0,05: H0 é aceita, a evidência de que as variações das médias entre os grupos de semestres são diferentes não é estatisticamente significante.
Como houveram violações dos pressupostos, vamos recorrer novamente aos métodos não-paramétricos.
| |
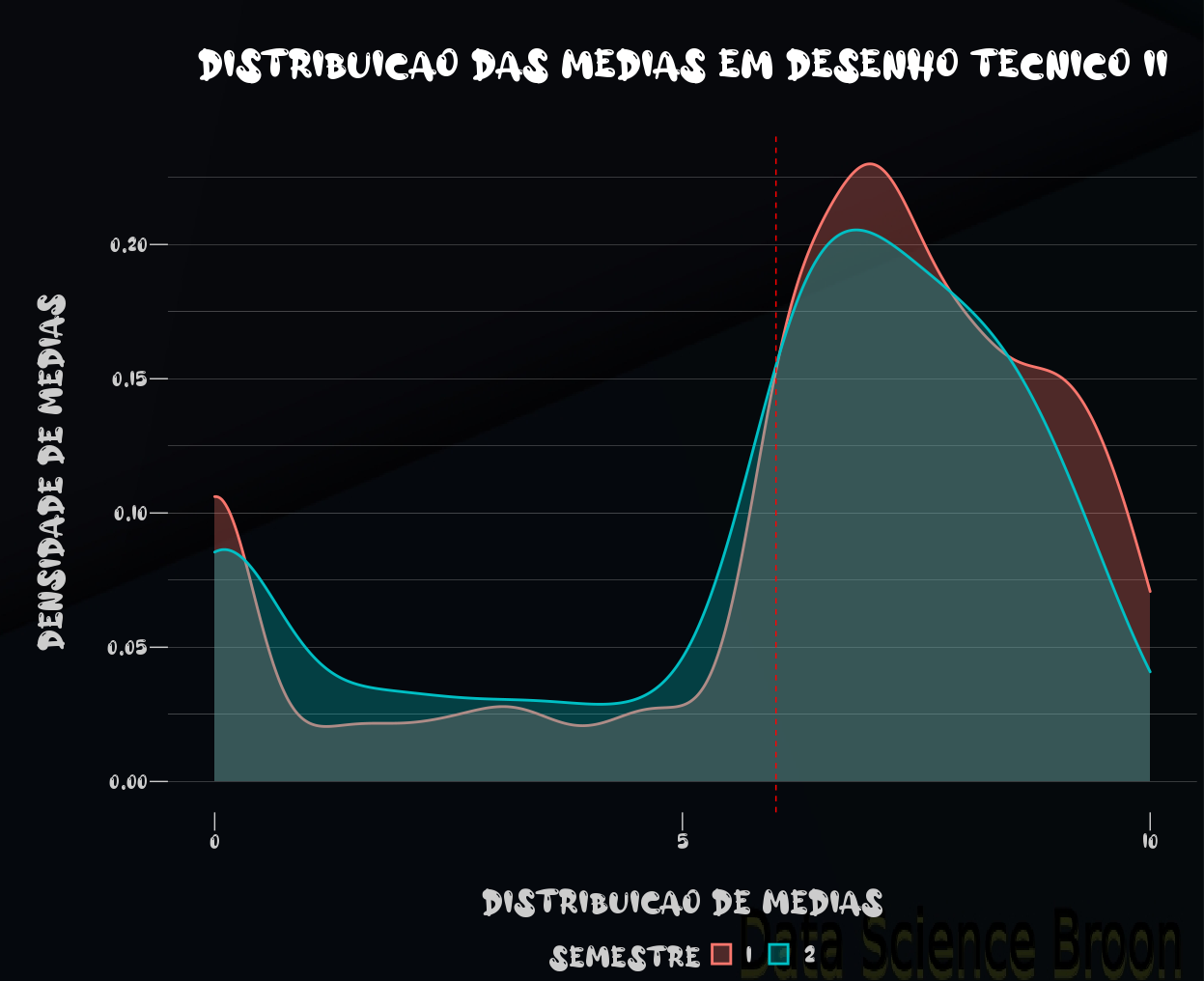
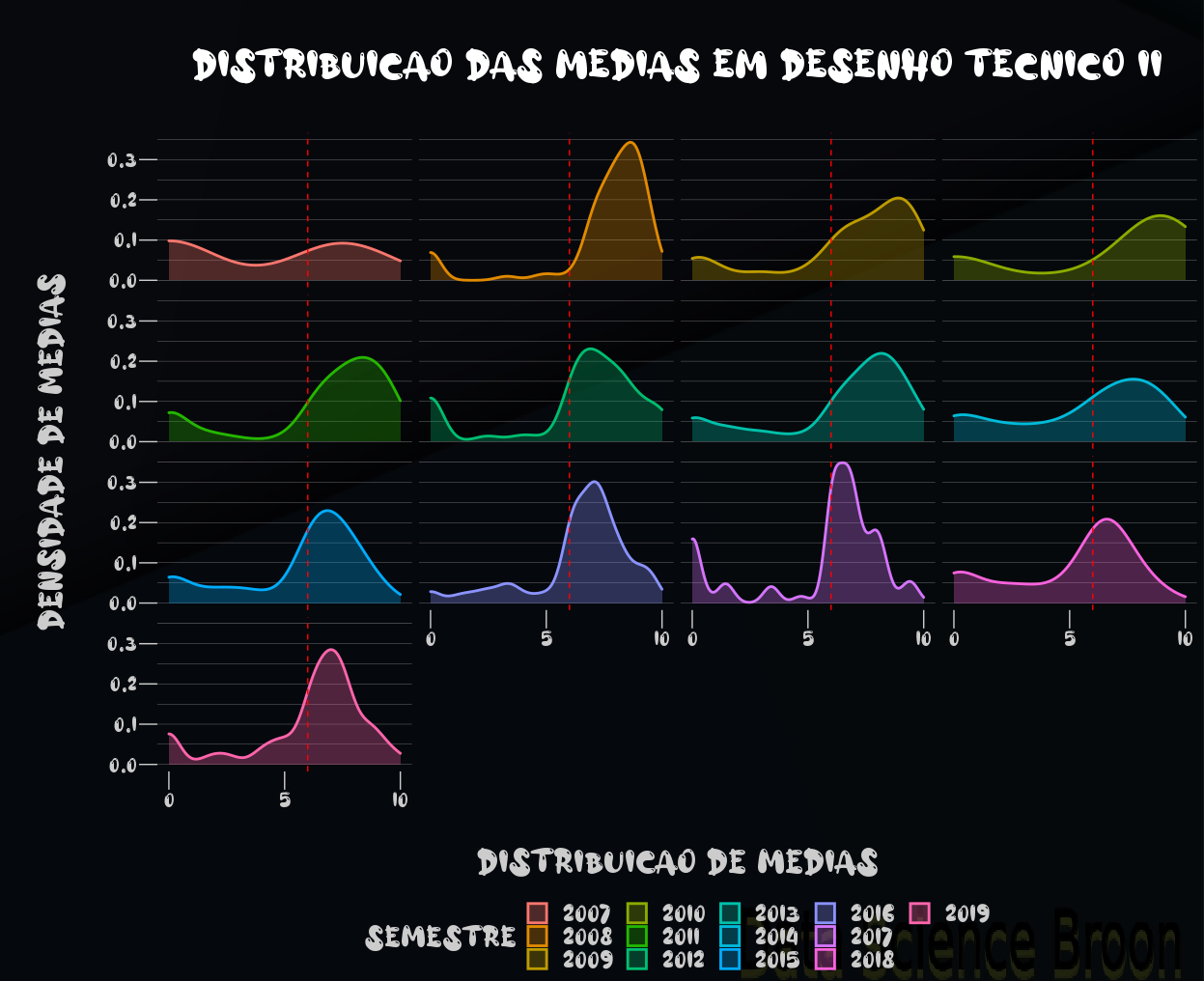
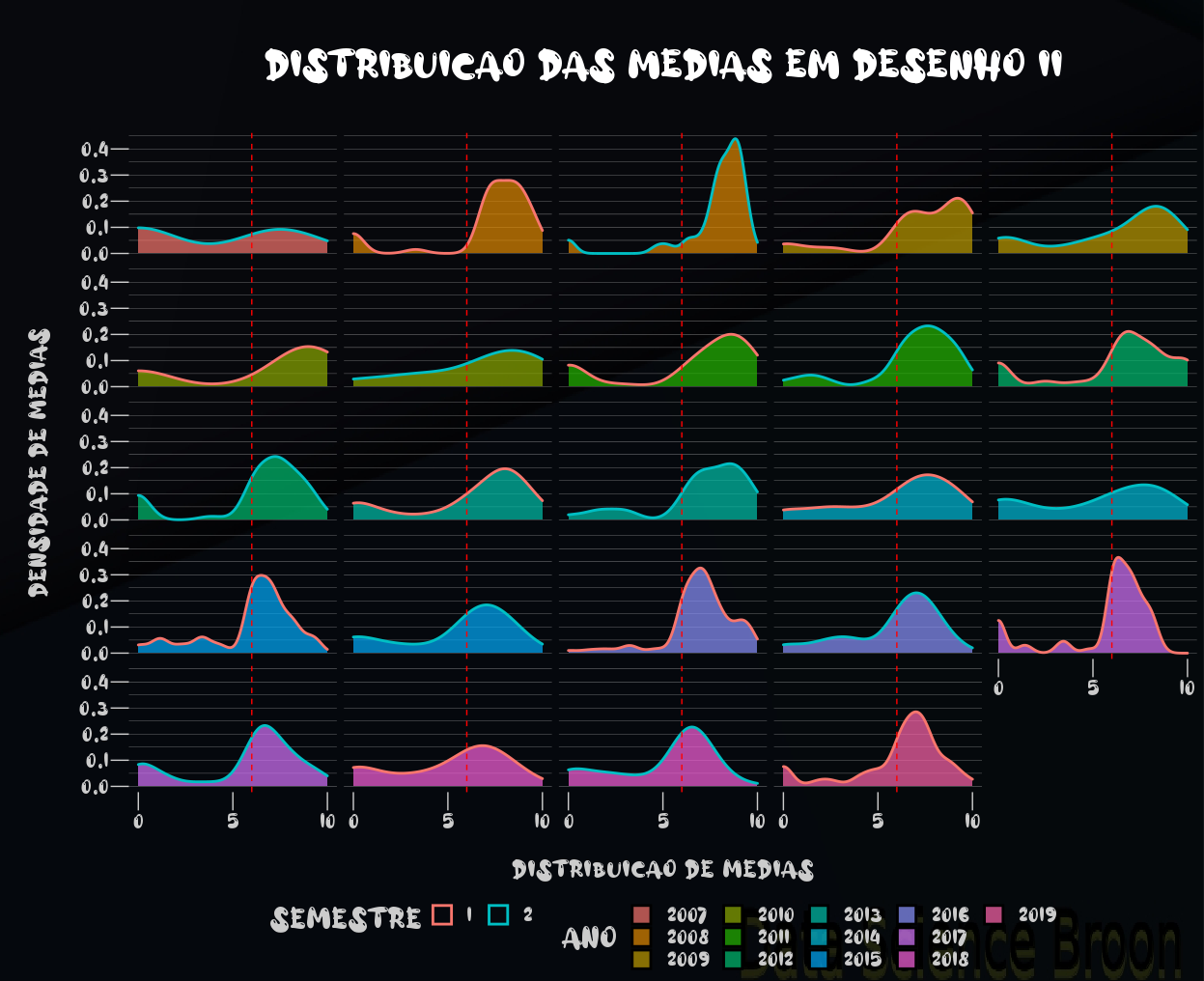
No caso dos semestres, as distribuições das médias possuem alguma semelhança. Ao verificarmos ano e ambos ano e semestre, as diferenças entre os grupos se mostraram mais significativas. Um resultado semelhante ao de Desenho Técnico I.
Agora vamos verificar quais grupos possuem semelhanças significativas.
| |
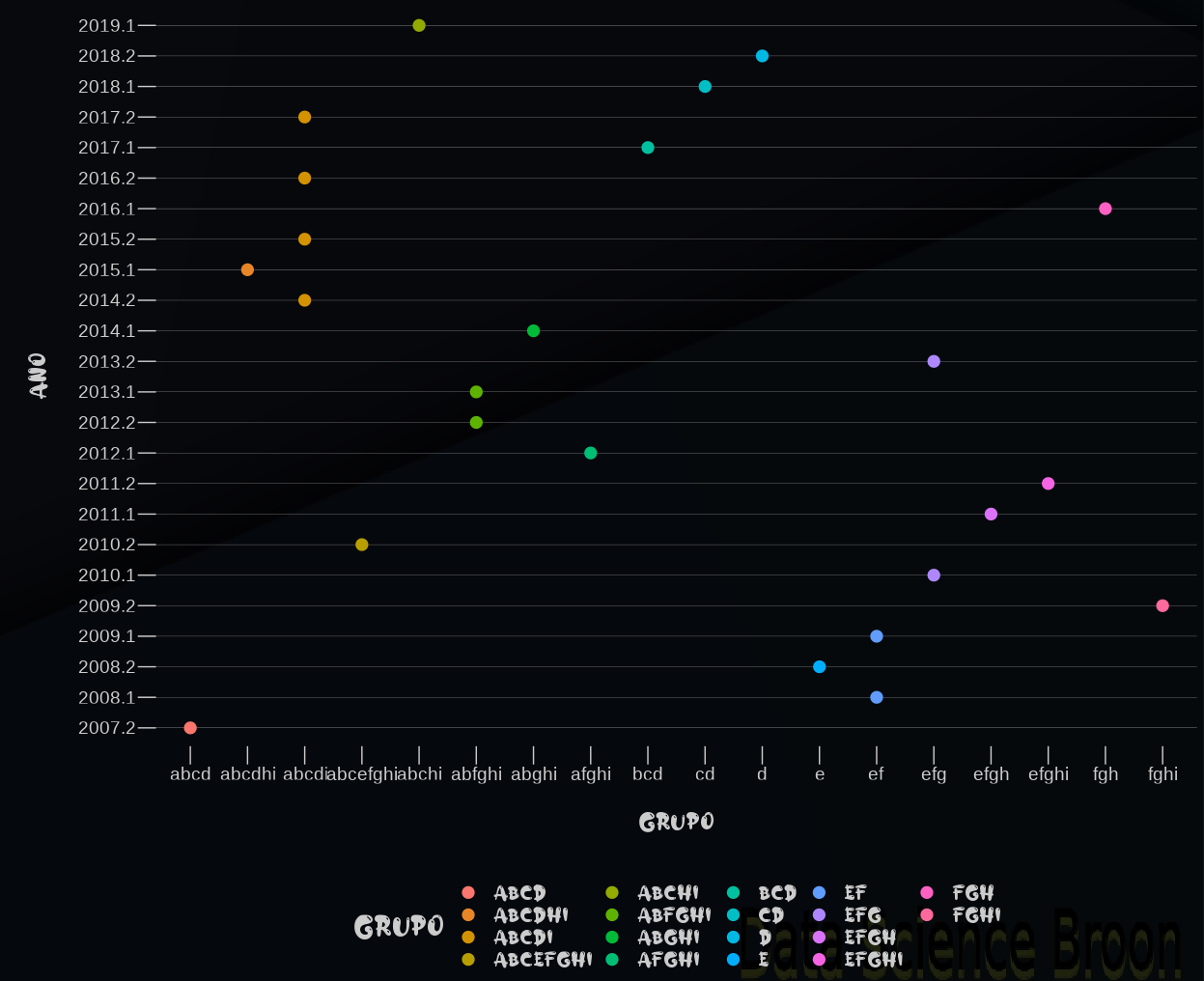
Os resultados até o momento são compatíveis com o que visualizamos na etapa dos gráficos, não é mesmo? Essa é uma das numerosas importâncias da estatística em nossas vidas: extrair valiosas informações de amostras de um universo de infinitas possibilidades, e esboçar possíveis considerações sobre elas.
O que foi possível extrair destas análises?
O curso de BAEQ tem médias superiores nos Desenhos comparada com outros cursos, enquanto que BALF possui desempenho inferior (e menor número de amostras);
Removidos os dados de reprovados por frequência, BAEC supera BAEQ em Desenho II nas estatísticas descritivas (porém, BAEC possui bem menos amostras que outros cursos);
Os grupos possuem um número muito diferente de amostras e isto não foi apresentado nos boxplots/violin plots;
A diferença entre as médias é significativa entre anos e semestres, anos, e em alguns casos, em semestres distintos, tanto em Desenho I como Desenho II.
Há uma tendência de redução geral do desempenho em Desenho II;
Estudantes do sexo feminino tem reprovado em menor quantidade e percentual do que estudantes do sexo masculino;
Uma quantidade significativa dos estudantes que reprovam por frequência em Desenho I e II acabam desistindo do curso, e uma parcela muito pequena acaba se formando ou permanecendo nos cursos;
A quantidade de reprovações são maiores no 1° semestre para Desenho I e no 2° para Desenho II. Faz sentido por Desenho I ser pré-requisito de Desenho II;
O desempenho médio em Desenho II é superior que em Desenho I em geral, e a quantidade de reprovados por frequência e por nota em Desenho II é menor do que em Desenho I;
Não há um padrão evidente na variação do desempenho se considerarmos apenas o ano/tempo como variável;
O que seria possível agregar para enriquecermos estes resultados?
Informações do docente que ministrou a disciplina, assim como suas características (mestrado/doutorado/substituto/graduação/…);
Demais informações dos estudantes, como forma de ingresso, notas no enem por área de estudo, se o estudante trabalha, etc;
Inclusão da forma de avaliação e formato de atividades adotado nas disciplinas;
Considerações Finais
Bom pessoal, a ideia foi apresentar um passo a passo detalhado sobre o processo de análise exploratória de dados utilizando o R. Além disso, incluímos análises estatísticas para verificar diferenças entre grupos de médias, como diferenças entre cursos, anos, semestres e outras variáveis.
Espero que vocês tenham gostado do post e que ele tenha auxiliado vocês de alguma forma.
Agradeço especialmente ao professor Dr. Alexandro Schafer por ter compartilhado este dataset comigo, possibilitando a realização destas análises.
Quaisquer dúvidas, podem deixar comentários logo abaixo :-)
Valeu !! Até o próximo post !! :-) (refêrencias logo abaixo).
Referências
Conjunto de dados de alunos de Desenho Técnico. Acesso em: 15 de maio de 2020.
Effect of variance ratio on ANOVA robustness: Might 1.5 be the limit?. Acesso em: 16 de maio de 2020.
MultiVDA - Pairwise Vargha And Delaney’s A And Cliff’s Delta. Acesso em: 16 de maio de 2020.
Undestanding boxplots. Acesso em: 16 de maio de 2020.